

Из изучения и анализа патентов поисковых систем, описывающих принципы работы поисковых алгоритмов, можно извлечь пользу и использовать полученные знания на практике в продвижении.
Алгоритмы поисковых систем основаны на решениях, которые описаны в патентах.
Рассмотрим патент Google, описывающий методы определения смысловых структур в тексте.
Обнаружение неявно определенных семантических структур в документе
Алгоритм поиска смысловых структур от Google называется обнаружение неявно определенных семантических структур в документе.
Исходя из содержательной части патента, поисковая система рассчитывает семантическую, а не визуальную близость элементов.
Согласно патенту, семантическая близость слов из элементов списка в отношении к заголовку списка одинакова.
Например, рассмотрим следующей список.

Поскольку каждый элемент списка, о котором идет речь, касается Сатурна (исходя из текста заголовка списка), можно сказать, что семантически каждый элемент списка в равной степени относится к ключевому слову Сатурн с точки зрения близости, хотя перечисленные в списке элементы находятся визуально на разном расстоянии от заголовка списка.
Исходя из алгоритма вычисления семантической близости следует вывод, что документ сайта одинаково релевантный ключевым словам "Saturn Mass", "Saturn Volume", and "Saturn Rotation".
Поэтому для поискового продвижения сайта нет никакого смысла спамить ключевыми словами в каждом элементе списке.
В приведенном выше примере слово "Saturn" (из заголовка списка) и "Distance" (из последнего списка) считаются более близкими, чем слова "Days" и "Rotation", хотя "Days" — это последнее слово первого элемента списка, а "Rotation" — это первое слово второго элемента списка.

Забавно? Не знали? А что об этом думаете — напишите в комментариях.
Патент от Google представляет некоторые интересные идеи о том, как поисковая система может проводить анализ семантических структур, таких как списки, чтобы определить, насколько страница релевантна для конкретного запроса.
Методы определения семантической близости более детально описаны в патенте Document ranking based on semantic distance between terms in a document.
Патент доступен по следующей ссылке — Обнаружение неявно определенных семантических структур в документе.
Исходя из содержания патента, основной вывод — расстояние между словами рассчитываются в зависимости от семантической разметки, а не от расстояния между словами.
В патенте указано, что значения расстояний могут использоваться при ранжировании и оценке документов сайта.
Также поисковая система Google умеет определять типы контента на странице сайта, даже если в документе сайта нет специальной разметки.
Например, списки должны создаваться тегами ul или ol и li, но поисковая система определит списки, даже при использовании других тегов. Например, система точно определит списки, если список элементов задан через:
- Тег таблицы table и тегов tr;
- Теги div;
- Теги переноса строки br.
В патенте прописано и то, что процесс поиска и определения может также применяться для поиска других значимых семантических структур.
Если в документе пропущен тег заголовка h1, то поисковая система может определить заголовок страницы исходя из размера шрифта, например если значение шрифта будет большим.
Другими словами, поисковая система пытается найти и определить визуальные структуры на странице. Но только те, которые могут быть семантически значимыми.
Как определить оптимальное количество вхождений ключевых слов в тексте
В поисковых системах текстовый фактор находится в перечне основных факторов ранжирования сайтов.
Плотность вхождения ключевых слов влияет на позиции сайта. Оптимальное значение изменчиво и зависит от тематики продвигаемого сайта.
Наилучшим способом для определения оптимального количества вхождений ключевых слов в тексте является анализ сайтов лидеров поиска.
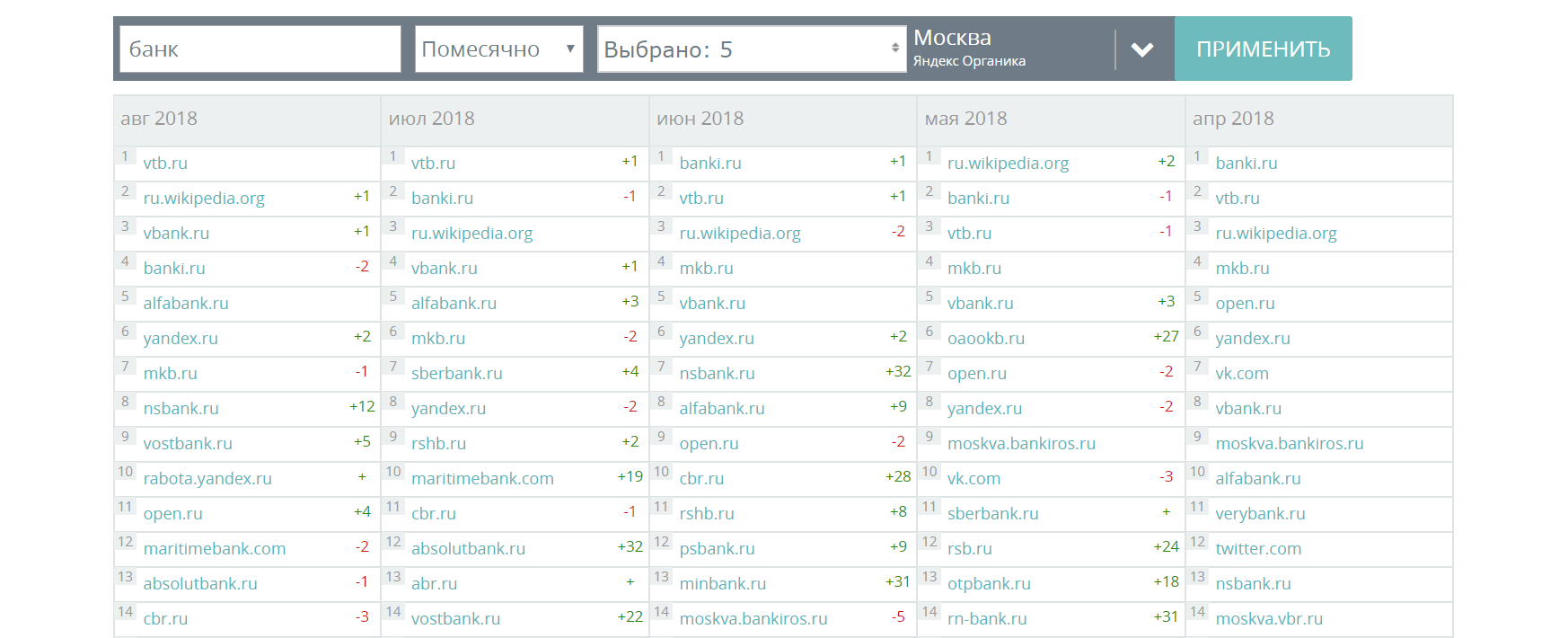
Сначала следует провести анализ органической выдачи поисковой системы и найти растущие сайты.
Провести анализ можно используя сервис MegaIndex или выгружая данные из MegaIndex API.
Ссылка на сервис — История выдачи по запросу.
Также поисковый оптимизатор может использовать API для выгрузки данных по видимости сайта в поисковых системах.
Выгрузка данных с использования API происходит посредством методов. Полный список методов доступен по следующей ссылке — MegaIndex API.
Для выгрузки данных по видимости сайта следует использовать метод visrep.
Пример запроса для сайта indexoid.com
http://api.megaindex.com/visrep?key={ключ}&domain=indexoid.com&ser_id=1При выгрузке видимости сайта может быть произведена сортировка по эффективным показам. Подробнее про эффективные показы в материале на сайте MegaIndex по следующей ссылке — Как на своем сайте найти страницы, которые необходимо оптимизировать первыми и которые принесут высокий возврат на инвестиции — Эффективные показы.
Пример запроса для сайта smmnews.com
http://api.megaindex.com/visrep?key=&domain=perevozim.ru&ser_id=1&sort=eff_volume
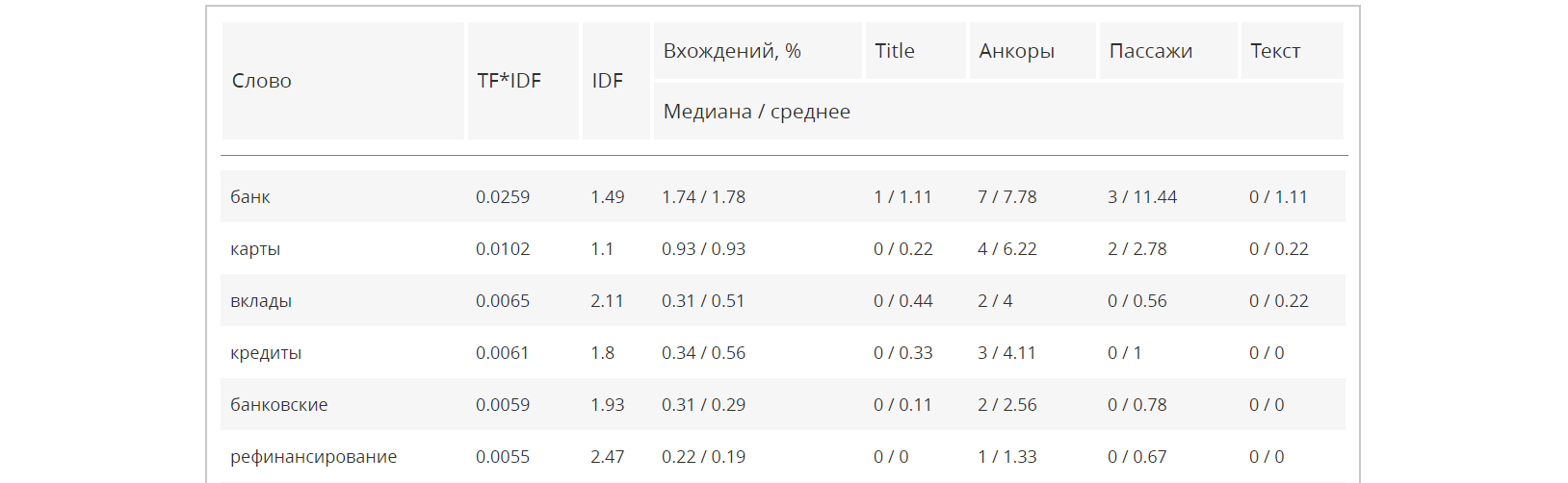
После завершения поиска растущих сайтов в заданной тематике, следует определить вхождение ключевых слов на найденных сайтах.
Анализ текста сайта можно провести через сервис от MegaIndex.
Ссылка на сервис — Анализ текста.
Выводы из патента
Главные выводы для поискового оптимизатора в следующем:
- Нельзя спамить ключевыми словами в каждом элементе списка;
- Ключевые слова следует размещать в заголовке списка и в начале элементов списка.
Изучение поисковых алгоритмов и последующее выполнение работ по продвижению сайта позволит догнать и перегнать конкурентов в поисковой выдаче.
Перечень дальнейших работ
После написания текстов и технической оптимизации сайта, следует заняться вопросами по привлекательности сниппетов в органической и рекламной выдаче.
Например:
Обсуждение
https://triumphessays.com/