
К внутренней оптимизации сайта относится и реализация JavaSript скриптов на сайте.
Эксперты Google представили новую информацию по теме использования JavaScript в контексте поисковой оптимизации сайтов под Google.
Актуальность вопроса
Поисковая система Google поддерживает JavaScript технологии и разрабатывает решения в целях улучшения индексации и ранжирования сайтов с элементами JavaScript.
Создание сайта, который привлекает пользователей, но хорошо при этом ранжируется в органической выдаче поисковой системы Google, требует сочетания определенных технологий на стороне сервера и на стороне клиента.
Технологии по созданию и развертыванию сайтов с элементами JavaScript развиваются. В интернете появляются приложения, созданные при помощи JavaScript-фреймворков.
При создании проектов используются разные стеки технологий. Часто используются:
- Angular;
- Polymer;
- React.
В поисковой системе Google разрабатываются общие решения для анализа подобных сайтов и создаются рекомендации по созданию search-friendly сайтов с использованием JavaScript.
Тема JavaScript и search-friendly сайтов рассматривалась на конференции Google I/O '18.
Видео
В своей презентации Deliver search-friendly JavaScript-powered websites на Google I/O 2018 Tom Greenaway и John Mueller поделились подробностями о том, как работает поисковый робот Google, и рассказали о лучших методах создания search-friendly сайтов и веб-приложений.
Еще видео от Google
Выводы
Основные заметки из доклада на конференции:
- В интернете более 130 триллионов документов;
- Робот Googlebot больше не сканирует URL-адреса с хэш. Пример hashbang ссылки — indexoid.com/#backlinks;
- Рендеринг JavaScript-в Google откладывается до тех пор, пока не станут доступны все ресурсы для обработки контента;
- Рекомендуется настроить систему для обнаружения обращений Googlebot к сайту и отдавать поисковой системе уже сгенерированный контент в формате html;
- Есть инструменты от Google для динамического рендеринга контента, такие как Puppeteer и Rendertron. Ссылка на Google Puppeteer — github.com/GoogleChrome/puppeteer. Ссылка на Google Rendertron — github.com/GoogleChrome/rendertron;
- Робот Google использует Chrome 41 для рендеринга скриптов JavaScript. Эта версия Chrome была выпущена в 2015 году и не поддерживает ES6;
- Google Search Console позволяет просматривать HTML-код, отрендеренный роботом Google, а также просматривать JavaScript исключения и лог;
- Если продвигаемый сайт использует так называемую ленивую загрузку изображений, добавьте тег noscript вокруг тега изображения, чтобы убедиться, что робот Google сканирует изображения;
- Google не индексирует изображения, на которые поставлены ссылки из CSS;
- Робот Googlebot сканирует и рендерит страницы без сохранения состояния, то есть не поддерживает service workers, local storage и сохранение сессий, куки, Cache API, Web SQL и прочее;
- Google планирует улучшения по процессу сканирование-рендеринг-индексирование. Робот Google будет использовать более современную версию Chrome для рендеринга документов сайтов.
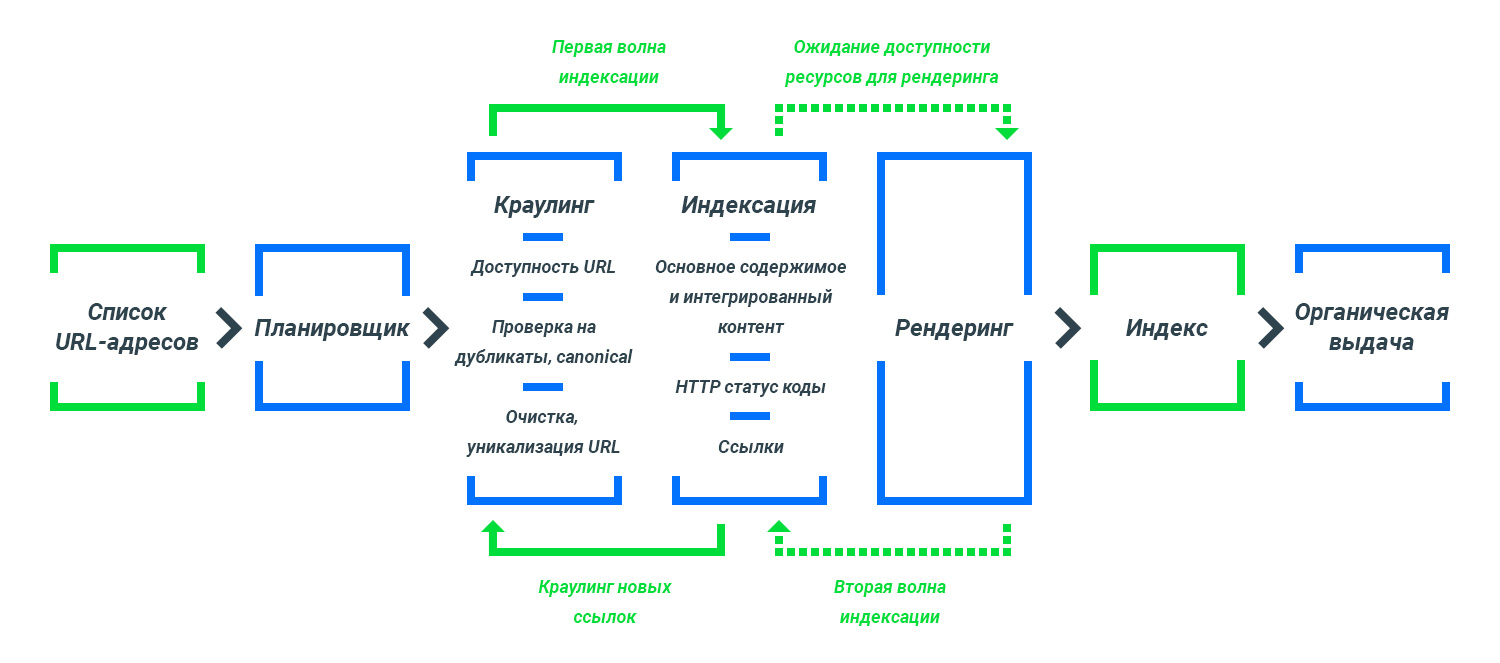
Как сайты попадают в поисковую выдачу
Процесс попадания сайтов в поисковую выдачу состоит из множества этапов. Этапы:
- Сбор списка ссылок для индексации;
- Обработка списка специальным планировщиком;
- Краулинг страниц;
- Рендеринг страниц;
- Индексация страниц;
- Попадание в базу индекса поисковой системы;
- Попадание в результаты органической выдачи поисковой системы.
Весь процесс в виде инфографики представлен далее.
Этап краулинга документов сайта
На этапе краулинга поисковая система выполняет ряд действий. При краулинге выполняется следующий набор задач:
- Анализ директив robots;
- Анализ тегов rel=canonical на предмет определения основной страницы;
- Анализ страниц на дубликаты;
- Удаление хвоста hashbang ссылок.
Хеш ссылкой называется ссылка с добавлением в хвосте символов после знака #.
Примеры ссылок:
Обычно идентификаторы фрагментов после знака # в URL-адресах обозначают разные местоположения информации на одной и той же странице. Поисковые системы, такие как Google и Yandex, считают, что подобные ссылки ссылаются на одну страницу сайта.
С применением новых JavaScript технологий через идентификаторы фрагментов после знака # стала доступна загрузка контента. Поисковая система Google не исполняет подобный код и не видит контент на сайте, подгружаемый подобным образом.
На этапе краулинга происходит обработка тегов rel=canonical. Значение в теге rel=canonical может указывать на внешний ресурс.
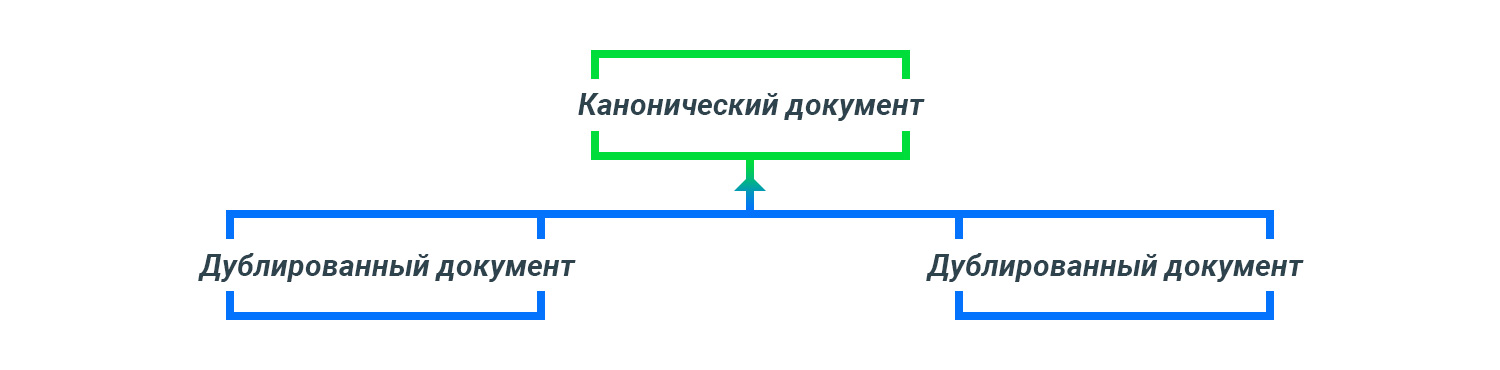
Эксперименты по анализу передачи статического веса с использованием rel=canonical не проводились.
Эксперимент провести очень просто. Процесс:
- Найти дроп с авторитетным ссылочным профилем. Для поиска можно использовать бесплатный сервис от MegaIndex. Ссылка на сервис — Удаленные домены;
- Поставить rel=canonical на внешний ресурс;
- Провести анализ влияния на позиции в органической выдаче поисковой системы.
Этап индексации документов сайта
На этапе индексации происходит обработка множества данных. Анализируется следующие:
- Содержание документа и интегрированного контента. Под интегрированным контентом подразумевается загрузка контента с внешних источников;
- Анализ кодов ответа;
- Обработка данных по ссылкам.
Поисковая система индексирует не все ссылки. Рассмотрим примеры.
Подобная ссылка подлежит индексации — smmnews.com. Код ссылки:
<a href="https://smmnews.com" target="_blank">smmnews.com</a>
Не подлежит индексации:
<span onclick="changePage('bad-link')">MegaIndex</span>Не подлежит индексации:
<a onclick="changePage('bad-link')">MegaIndex</a>Подлежит индексации:
<a href="/link" onclick="changePage('good-link')">MegaIndex</a>Этап рендеринг документов сайта
Если на сайте используется тяжелый код JavaScript, то добавление страницы в индекс поисковой системы не будет происходить быстро.
Рендеринг страницы будет отсрочен до момента появления у Googlebot ресурсов для обработки контента.
По причине ограниченности технических ресурсов Google, индексация документов с тяжелыми javascript файлами происходит с отсрочкой.
Решение задачи по быстрой индексации заключается в использовании технологий пререндеринга от Google.
Google Dynamic Renderig и Hybrid Rendering
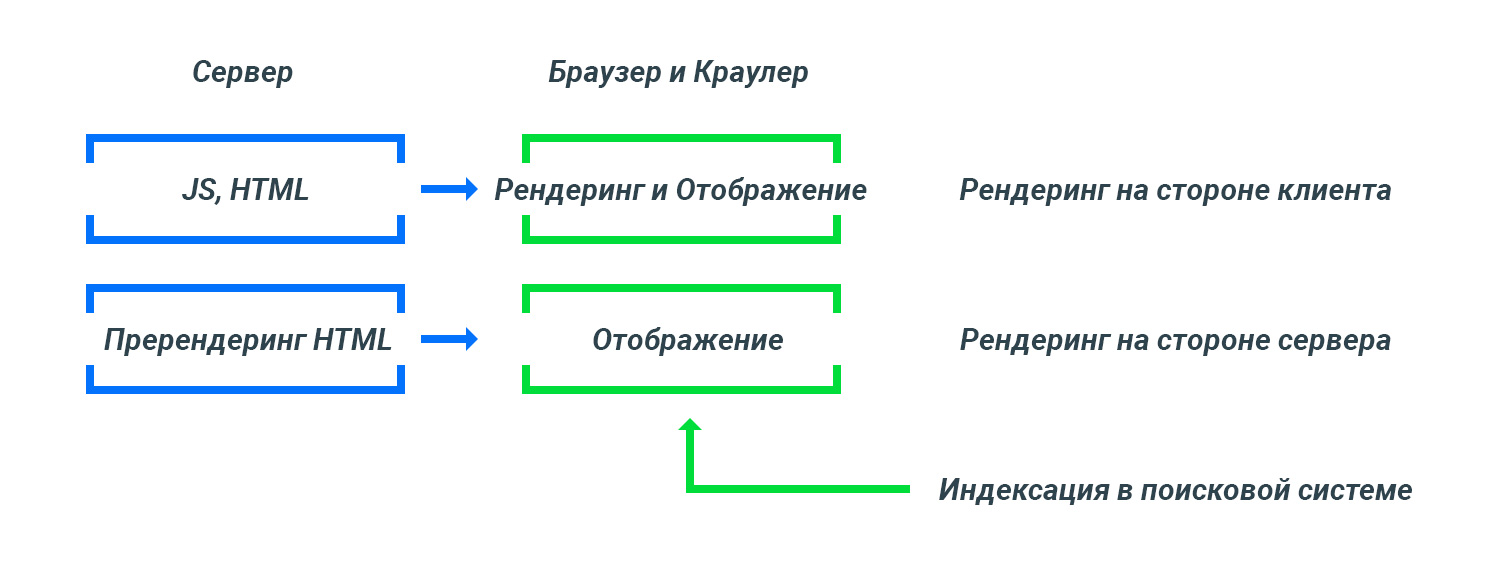
Есть инструменты от Google Dynamic Renderig для динамического рендеринга контента, такие как Puppeteer и Rendertron.
Подобные инструменты позволяют проводить рендеринг страниц на стороне сервера. В результате, поисковый робот получает готовый результат в виде полноценной страницы с выполненным JavaScript. Подобные страницы быстро попадают в индекс поисковой системы.
Ссылка на Google Puppeteer — github.com/GoogleChrome/puppeteer.
Ссылка на Google Rendertron — github.com/GoogleChrome/rendertron.
При необходимости подобные технологии можно использовать для формирования результата только для поисковой системы, пользователям сервер может отдавать результаты с javascript кодом.
Подобная технология не является черным клоакингом. Поисковая система адекватно обрабатывает подобный результат.
Использование подобной технологии рекомендуется для разных сайтов.
Примеры сайтов:
- Новостные сайты, на которых часто контент появляется;
- Сайты с тяжелым javascript кодом;
- Сайты с интегрированными блоками с внешних ресурсов.
Под интегрированными блоками с внешних ресурсов подразумеваются сайты с загружаемыми с внешних сайтов данными. Для примера:
- Онлайн чаты. Примеры подобной системы — Intercom;
- Видео с YouTube;
- Счетчики социальных сигналов.
Для реализации требуется определить обращение краулера поисковой системы и передать роботу готовый результат в виде статического документа. Если на сайте используются десктопная и мобильная версии, то каждую версии следует передать соотвествующему роботу.
Как определить, что к сайту обращается именно робот Googlebot? При обращении к сайту робот от Google использует специальный идентификатор.
Идентификатор робота Googlebot, сканирующего десктопную версию сайта:
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Идентификатор робота Googlebot, сканирующего мобильную версию сайта:
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Результата рендеринга сайта поисковой системой можно посмотреть используя инструменты Google.
Для рендеринга десктопной версии можно использовать Google Search Console.
Ссылка на инструмент — Google Search Console.
Для рендеринга мобильной версии можно использовать Google Mobile-Friendly Test.
Ссылка на инструмент — Google Mobile-Friendly Test.
Поисковая оптимизация Lazy Loading для изображений
Улучшение скорости загрузки документов сайта обеспечивают разные технологии. К примеру, часто используется технология javascript ленивой загрузки изображений сайта.
При использовании Lazy Loading загрузка изображений происходит на этапе вывода изображения на экран.
Поисковая система не видит подобные изображения.
Для поисковой оптимизации подобного участка кода рекомендуется использовать специальную разметку.
Есть два решения. Список решений:
- Тег noscript;
- Разметка для изображений по стандарту Schema.
Пример разметки:
<img class="lazy" alt="image" src="placeholder.jpg" data-src="image.png"> <noscript><img src="image.png"></noscript>
Решением индексации изображений является и использование специальной разметки для изображений по стандарту image от Schema.org.
Ссылка на документацию — https://schema.org/image.
Пример разметки для файла logo.png на сайте indexoid.
<script type="application/ld+json"> {
"image": "https://indexoid.com/logo.png"
</script>Поисковая оптимизация вкладок
Поисковая оптимизация требуется также при использовании кода JavaScript в других решениях по верстке документов сайта. Примеры решений:
- Навигация и использование табов, вкладок;
- Кликните для загрузки контента;
- Подгрузка при скроллинге;
- Тапните, чтобы посмотреть.
Есть разные решения по поисковой оптимизации для подобных элементов верстки сайта.
Основные решения:
- Использование предзагрузки контента на странице с применением кода CSS;
- Создание отдельной страницы с уникальным адресом страницы.
При поисковой оптимизации элементов сайта на JavaScript:
- Используйте лучшие практики описанные выше;
- Протестируйте рендеринг на всех типовых страницах сайта;
- Если надо, используйте Dynamic Rendering. Протестируйте изменения на практике, после внедрения улучшений.
Какие решения используете Вы?
Обсуждение
Но ведь там, как правило, комментарии к статьям и блогам?? А это как известно, наряду с guest posting один из мощнейших инструментов продвижения.