

Если копия контента размещена на стороннем сайте и проиндексирована, то поисковая система может определить копию как оригинал и выводить в поисковой выдаче страницу с копией выше за оригинал.
Далее рассмотрим тему о защите контента с технической стороны. Список рассматриваемых вопросов:
- Как на уровне сервера защитить контент от воровства конкурентами и профессиональными монетизаторами?
- Как уведомить поисковую систему об оригинальном источнике контента?
- Как извлекать пользу из копий, например если картинки были скопированы другими сайтами?
Защита контента на уровне сервера
Итак, как на уровне сервера защитить контент от воровства со стороны конкурентов и профессиональных монетизаторов?
Главными инструментами для копирования контента являются так называемые системы парсинга. Есть набор превентивных мер по защите сайта от большинства систем парсинга.
Для защиты требуется обнаружить среди посетителей сайта автоматический парсер и заблокировать систему на уровне сервера.
Есть пару простых способов для решения задачи:
- Проверка на JavaScript;
- Проверка на действие.
Проверка на JavaScript
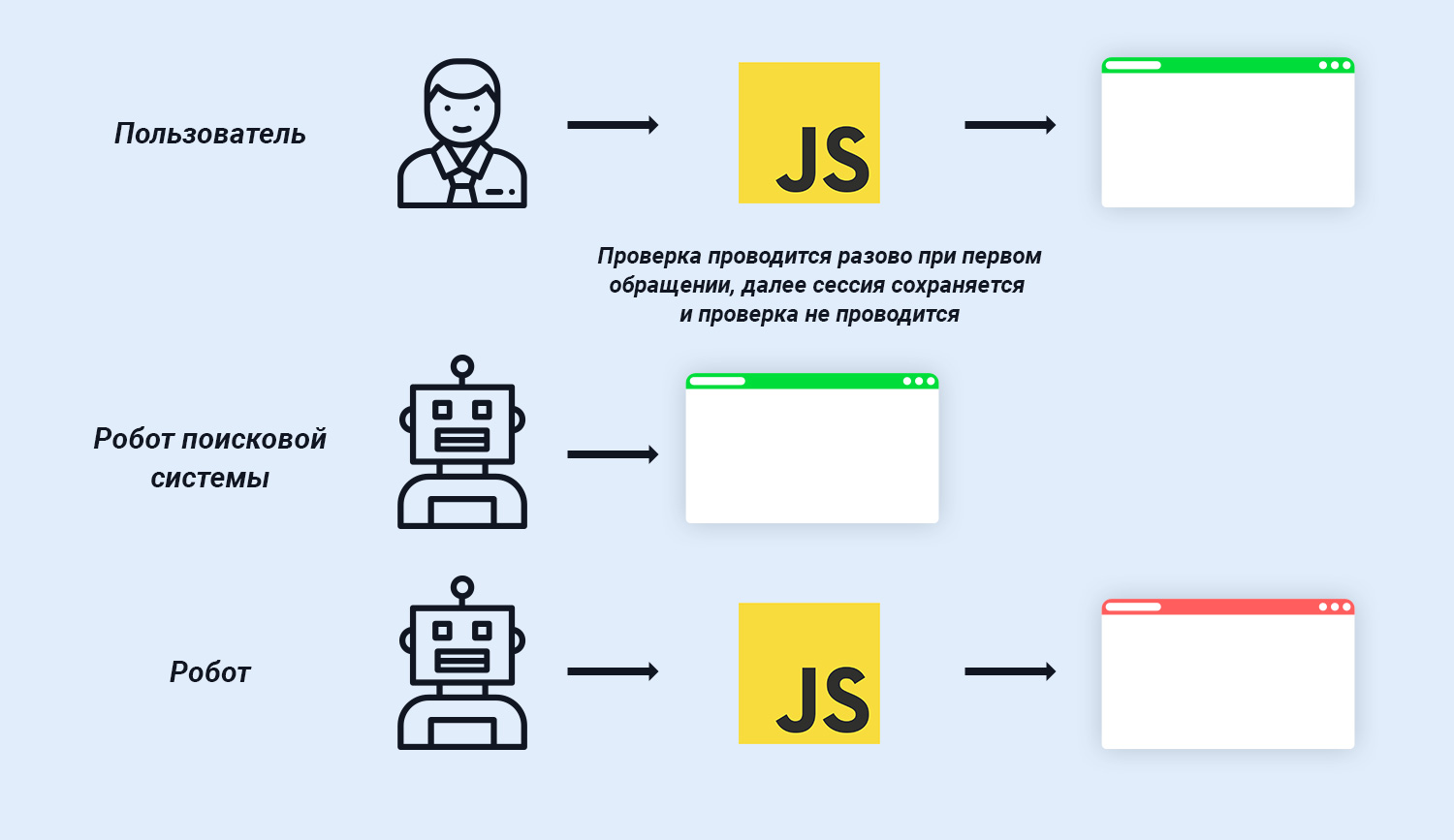
Большинство систем парсинга являются технологически простыми инструментами, не имитирующими действия пользователя.
На практике все подобные системы очень просто распознать путем проверки на использование JavaScript.
Если JavaScript не выполняется в принципе, значит с высокой вероятностью сайт посещает робот, и подобные обращения могут быть заблокированы.
Процент пользователей с полностью отключенным JavaScript ничтожно мал, но все же глупо лишаться любого органического трафика. Как альтернатива, вместо полной блокировки запросов, клиенту можно предлагать пройти капчу. Если использовать любую простую капчу, то целевой трафик останется на сайте, а системы парсинга будут заблокированы на уровне сервера.
В исключения на блокировку следует добавить краулеров поисковых систем.
Поисковые системы используют стандартные имена краулеров, не меняя их при обращении к любым сайтам. Списки названий краулеров доступны в документации на официальных сайтах поисковых систем.
Список названия краулеров Google доступен по следующей ссылке — Поисковые роботы Google (агенты пользователя).
Список названия краулеров Yandex доступен по следующей ссылке — Yandex robots.
Проверка на действие

Есть еще один простой и действенный способ защиты сайта от большинства систем парсинга, без проверки на JavaScript.
Итак, более умные системы парсинга имитируют включенный JavaScript. Но есть способ обнаружить систему парсинга, даже если робот использует JavaScript.
Решение задачи базируется на анализе целей и принципов работы систем парсинга. Главная задача парсера заключается в скачивании ценного контента с сайта.
К примеру, если система парсинга скачивает статьи с новых страниц сайта, то задачей системы является скачивание заголовка страницы и содержания статьи.
Система парсинга не будет скачивать все ресурсы страницы сайта. Решение по обнаружению робота следует исходя из логики функционирования парсера.
Итак, процесс обнаружения и отсечения запросов от систем парсинга следующий:
- На странице с контентом размещаются разные картинки. Следует выбрать картинку за пределами блока статьи. К примеру, можно выбрать картинку любого элемента навигации, логотип или просто создать картинку размером 1px на 1px;
- Картинка 1px на 1px закрывается в display none;
- Открытие страницы пользователем через браузер подразумевает загрузку картинки в автоматическом режиме;
- Запрос к картинке является отдельным запросом. Запрос на загрузку картинки отображается в логах сервера как отдельный запрос к файлу;
- Если к сайту идет обращение от системы парсинга, то запрос на контент страницы будет отображаться в логах сервера, но запроса на картинку не последует, поскольку подобный файл не интересен копипастеру и не обрабатывается системой парсинга;
- Далее путем анализа логов сервера происходит сбор IP парсеров и проводится блокировка доступа к сайту.
Подобный процесс обнаружения парсеров поддается полной автоматизации.
Запретить доступ к сайту с определенных IP крайне просто. Для ограничения доступа можно использовать файл директив сервера .htaccess.
Пример с smmnews.com:
- Order allow,deny
- allow from all
- deny from 1.1.1.1
Эффективные и простые варианты по обнаружению систем парсинга описаны выше. Как альтернатива, есть иные варианты:
- Расчет скорости клика на основе данных из статистики. Если клиент кликает по ссылкам крайне быстро, значит за запросами стоит робот;
- Полное сканирование сайта роботом можно определить используя тест на клик. В шаблоне статьи можно создать ссылку по которой пользователь не может кликнуть. К примеру, ссылку можно скрыть путем использования display none. Далее можно фиксировать IP с которых осуществляются запросы к документу, расположенному по скрытой ссылке. Как результат, есть возможность собрать список ботов, которые посещают сайт и заблокировать при необходимости.
Наиболее эффективный и сложный вариант заключается в анализе движения курсора на сайте.
Карта сайта Sitemap.xml
Как еще защитить контент от воровства?
На большинстве сайтов настроена генерация карты сайта sitemap.xml. Файл содержит исчерпывающий список ссылок на страницы сайта, подлежащие к индексации поисковыми системами.
Основное предназначение карты сайта заключается в оповещении поисковых систем о появлении новых страниц и обновлении текущих.
По умолчанию карта сайта располагается по адресу /sitemap.xml.
Пример адреса для сайта indexoid.
https://indexoid.com/sitemap.xml
Если карта размещена по стандартному адресу, система парсинга скачивает карту сайта раньше поисковой системы. Принцип функционирования подобного парсера простой:
- Благодаря стандартному расположению карты сайта sitemap, системы парсинга добираются и сканируют файл карты быстрее, нежели краулеры поисковых систем Google и Yandex;
- Парсер ищет новый контент;
- Далее контент публикуется на сайте с копиями;
- Затем проводится индексации контента поисковыми системами. Индексация проводится в ускоренном режиме благодаря специальным системам. К примеру, для ускорения индексации может использоваться GetSocial;
- Далее поисковые системы определяют копии как оригинальный источник контента, а оригинальные страницы, напротив, маркируются как копия.
Поисковым системам известны подобные схемы. Но на практике разбор подобных ситуаций является крайне сложной задачей.
Как решение, поисковые системы предоставляют специальные инструменты, используя которые можно указать путь к файлу карты сайта sitemap.xml.
Подобный инструмент есть в Google Search Console. Ссылка на сервис — Google Search Console Sitemaps.
И подобный инструмент есть в Yandex Webmaster. Ссылка на сервис — Yandex Webmaster. Страница для добавления карты сайта доступна по адресу Индексирование > Файлы Sitemap.
Защита контента в Yandex
Как уведомить поисковую систему об оригинальном источнике контента до публикации контента?
В инструментах веб-мастера от Яндекс предусмотрен сервис для отправки уведомлений о появлении оригинальных текстов в поисковую систему.
Сервис называется Оригинальные тексты. С помощью сервиса можно сообщить поисковой системе о новых страницах, чтобы при ранжировании результатов в поисковой выдаче учитывался фактор источника оригинального текста.
Для подтверждения текста достаточно заполнить форму. Ссылка на форму — Форма "Оригинальные тексты".
Важные нюансы:
- Яндекс не гарантирует учет заявки в работе поисковых алгоритмов;
- Текст следует добавить без тегов;
- Минимальный объем текста — 500 знаков;
- Максимальный объем текста — 32 000 знаков. Если объем текста превышает 32 000 знаков, то в таком случае стоит разбить текст на части и добавить частями;
- За день можно добавить максимум 100 текстов;
- Если текст был опубликован на ином сайте до подачи заявки, то заявка учитываться не будет.
Инструмент является предупреждающей мерой.
Исходя из алгоритмов поисковой системы, в органической выдаче должны появляется страницы с оригинальным содержанием, первоисточники.
Владельцам контента следует добавлять текст в сервис до публикации на сайте.
Защита контента в Google
В инструментах веб-мастера от Google подобные сервисы для отправки уведомлений о появлении оригинальных текстов в поисковую систему не предусмотрены.
Но есть меры для удаления копий из поисковой выдачи.
Детали по защите контента в поисковой системе Google изложены на блоге MegaIndex в материале по ссылке далее — Как удалить страницы конкурентов из поисковой выдачи, если на них размещен скопированный контент? Что такое DMCA?
В материале также рассматриваются следующие важные темы:
- Какой контент имеет смысл защищать от конкурентов?
- Что надо сделать, чтобы защитить контент?
- Как удалить страницы любого сайта из поисковой выдачи, если на страницах размещен хотя бы частично скопированный контент?
- Что такое DMCA?
Проверка текста на копии
Как проверить текст на копии? Проверка текста на копии проводится посредством специальных сервисов. К примеру, есть вариант использовать сервис от MegaIndex.
Ссылка на сервис — Проверка контента на уникальность.
Сервис бесплатный.
Мониторинг
Как узнавать о появлении новых копий контента? Для поиска и учета копий текстового контента можно использовать сервис по мониторингу упоминаний.
К примеру, поисковый оптимизатор продвигает сайт компании. Если в каждой статье упоминать название компании, то используя систему для отслеживания репутации в интернете можно отслеживать упоминания о компании и появление новых копий контента.
Проводить мониторинг упоминаний можно используя MegaIndex. Сервис называется MegaIndex Search Engine Reputation Management.
Ссылка на сервис — MegaIndex SERM.
Сервис бесплатный.
Пример найденных уведомлений по бренду.
После обнаружения копий следует провести работу по созданию претензий, целью которых может являться:
- Удаление копии контента с сайта;
- Удаление страницы с копией контента из поисковой выдачи;
- Размещение ссылки на оригинал.
Извлечение пользы из копий теста
Если скопирован текст, изображение или интерактивный элемент, то следует отправить запрос на размещение ссылки на оригинал.
Ссылка должна быть:
- Открытой для индексации;
- Передавать вес, быть dofollow.
Каждая dofollow ссылка передает статический и анкорный веса.
Используя большой набор ссылок со страниц копий можно значительно улучшить внешний ссылочный профиль сайта.
Извлечение пользы из копиий изображений
Как извлекать пользу из копий изображений? Есть два вида копий изображений:
- Изображение было загружено на сторонний сайт;
- Изображение было вставлено на сторонний сайт.
Итак, как извлекать пользу из копий изображений? На практике часто изображения вставляют на сайт, без загрузки. Как результат, изображение загружается с оригинального сайта, но выводится на стороннем сайте.
Если картинка вставлена, то на стороне сервера можно создать специальный скрипт, который бы при загрузке изображения с не оригинального хоста отдавал бы картинку с добавленным водяным знаком, к примеру логотипом бренда.
К примеру, если конкурентом с сайта магазина А были украдены оригинальные изображения на сайт магазина Б, то на сайте магазина Б вставленные изображения выводились бы с логотипом магазина А.

Зачем защищать контент?
Каждый заинтересованный пользователь открывает страницы различных сайтов в целях чтения или любого иного способа потребления контента, размещенного на странице.
Соответственно, контент сайта является основной ценностью для пользователя и главным подспорьем монетизации для владельцев сайтов.
Контент сайта является важным элементом при продвижении сайта ввиду следующих причин:
- Семантическое текстовое содержание и интерактивный контент страницы являются фактором ранжирования документов сайта в органической выдаче поисковой системы. Рекомендованный материал в блоге MegaIndex по теме латентно-семантического индекса по ссылке далее — Как собрать LSI семантику и получить бонус от поисковой системы при продвижении сайта?;
- Контент влияет на конверсии и лояльность пользователей к сайту;
- Контент влияет на пользовательские факторы, являющиеся фактором ранжирования для документа;
- Контент отдельно взятой страницы влияет не только на позиции данной страницы, но и на поведенческие факторы, относящиеся к хосту, а следовательно контент страницы влияет на ранжирование всех документов сайта.
На позиции сайта контент влияет и прямо, и опосредовано. Если вести речь о прямом влиянии контента на позиции сайта в органической выдаче поисковой системы, то в качестве примера следует указать следующие факторы ранжирования:
- Ответ на интент пользователя. Подробнее про интент на сайте MegaIndex по ссылке далее — Что такое интент;
- Охват ключевых фраз из латентно-семантического индекса;
- Частота обновления контента на сайте в целом;
- Актуальность контента на странице;
- Семантика страницы в плане ответа на целевой запрос из поисковой выдачи и потенциальные сопутствующие запросы по теме.
Если вести речь о косвенном влиянии контента на позиции сайта в органической выдаче поисковой системы, то в качестве примера следует указать на следующие факторы ранжирования:
- Поведенческие факторы, исходящие из анализа поведения пользователя на странице. Для примера, проведенное время на сайте;
- Взаимодействия. К примеру, клики, если на странице размещен интерактивный контент.
Рекомендованный материал в блоге MegaIndex по теме удаления страниц конкурентов из поисковой выдачи по ссылке далее — Как удалить страницы конкурентов из поисковой выдачи, если на них размещен скопированный контент? Что такое DMCA?
Есть ли что дополнить? Остались ли у вас вопросы по теме защиты контента?
Обсуждение
Thank. It would be interesting. how we can analyze the content written by a content writer on our website was copied.
Fleet Repair in mobile alabama