
Как настроить бесплатный парсинг данных с применением Google роботов для парсинга?
Разберемся с вопросом далее.
1 — Проблематика: Автоматизация сбора данных для аналитики из разных источников
Зачастую для аналитики требуются данные, которые размещены на разных источниках. Организовать сбор данных является задачей затратной по ресурсам.
Есть различные платные инструменты, которые помогают в решение задачи. Но покупать подписку на такие сервисы в большинстве случаев необязательно. Есть бесплатный способ.
Сначала разберемся каким критериям должна обладать идеальная система парсинга? Работу по парсингу следует поручить роботам, так работа упрощается и выполняется без ошибок. Система сбора данных должна легко настраиваться.
Еще лучше, если настройки для парсинга сохраняются. В идеале, все должно быть бесплатным.
Такая система есть у Google. Среди поисковых оптимизаторов и маркетологов многие пользуются таблицами Google. Но мало кто знает про IMPORTXML.
Как использовать бесплатный парсинг за счет Google?
Как поставить себе на службу краулеров Google?
2 — Решение: Бесплатный сбор данных для аналитики средствами Google
IMPORTXML является функцией Google Spreadsheet, которая позволяет использовать роботов Google для парсинга данных из внешних источников.

Скорость высокая. Сбор данных происходит за счет Google. То бишь инструмент для пользователя является бесплатным.
Из каких источников допускается импорт данных? Список:
- Страницы с разметкой HTML;
- XML;
- CSV;
- TSV;
- RSS;
- ATOM XML.
Функция IMPORTXML позволяет сканировать страницы сайтов, проводить выгрузку ссылок, заголовков title, различных тегов и так далее.
По сути данная функция способна заменить многие платные инструменты, которые предлагаются специалистам по поисковой оптимизации.
Как использовать? Синтаксис следующий:
IMPORTXML(ссылка; запрос_xpath)
Значение параметра ссылка должно быть заключено в кавычки или представлять собой ссылку на ячейку, содержащую соответствующий текст.
Значение параметра запрос_xpath используется для поиска данных. Через путь XPath бот получает информацией о требуемой информации.
Подробнее про XPath — XPath. Пишите в комментариях вопросы, если интересно.
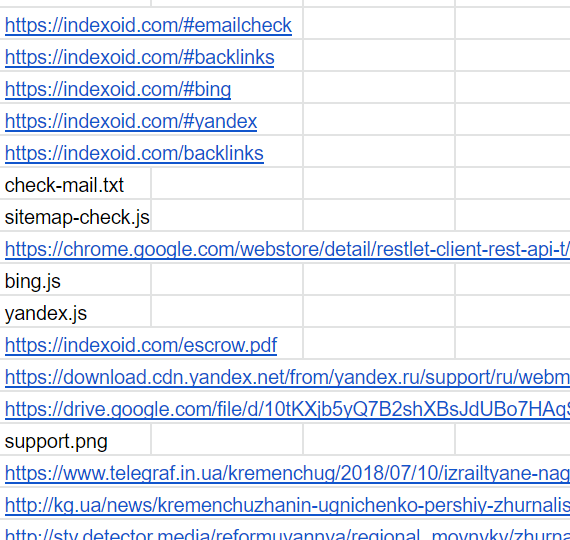
Пример использования. Выгрузка всех ссылок с сайта indexoid.
=IMPORTXML("https://indexoid.com", "//a/@href")Результат:
IMPORTXML крайне удобно использовать в разных сценариях для построения мелких отчетов. На практике я использую IMPORTXML для анализа новых роликов на YouTube за период. Анализирую как конкурентные каналы, так и продвигаемый канал.
IMPORTXML для YouTube
Количество дизлайков парсится так:
=if(isna(importxml(C3,"(//*[contains(@class,'like-button-renderer-dislike-button')])[1]"))=TRUE,0,importxml(C3,"(//*[contains(@class,'like-button-renderer-dislike-button')])[1]"))
Количество лайков парсится так:
=if(isna(importxml(C3,"(//*[contains(@class,'like-button-renderer-like-button')])[1]"))=TRUE,0,importxml(C3,"(//*[contains(@class,'like-button-renderer-like-button')])[1]"))
Количество просмотров парсится так:
=value(REGEXREPLACE(text(importxml(C3,"//*[contains(@class, 'watch-view-count')]"),0)," view(s)?",""))
Чтобы было проще, подготовил шаблон. Пользуйтесь.
Ссылка на шаблон — YouTube.
IMPORTXML для SEO
ImportXML позволяет использовать Google робота для сканирования любых сайтов, которые доступны.
Как выгрузить Title страницы? XPath следующий:
//title/text()
Как выгрузить Meta Descriptions страницы? XPath следующий:
//meta[@name='description']/@content
Как выгрузить canonical страницы? XPath следующий:
//link[@rel='canonical']/@href
Как выгрузить h1 страницы? XPath следующий:
//h1/text()
Как внутренние ссылки страницы? XPath следующий:
"//a[contains(@href, 'доменное_имя')]/@href"
Как внешние ссылки страницы? XPath следующий:
"//a[not(contains(@href, 'доменное_имя'))]/@href"
Ссылки на сети:
"//a[contains(@href, 'linkedin.com/in') or contains(@href, 'twitter.com/') or contains(@href, 'facebook.com/')]/@href";
Найти различные проблемы на сайте способен инструмент по аудиту сайтов от MegaIndex.
Пример отчета для сайта SEOHero.
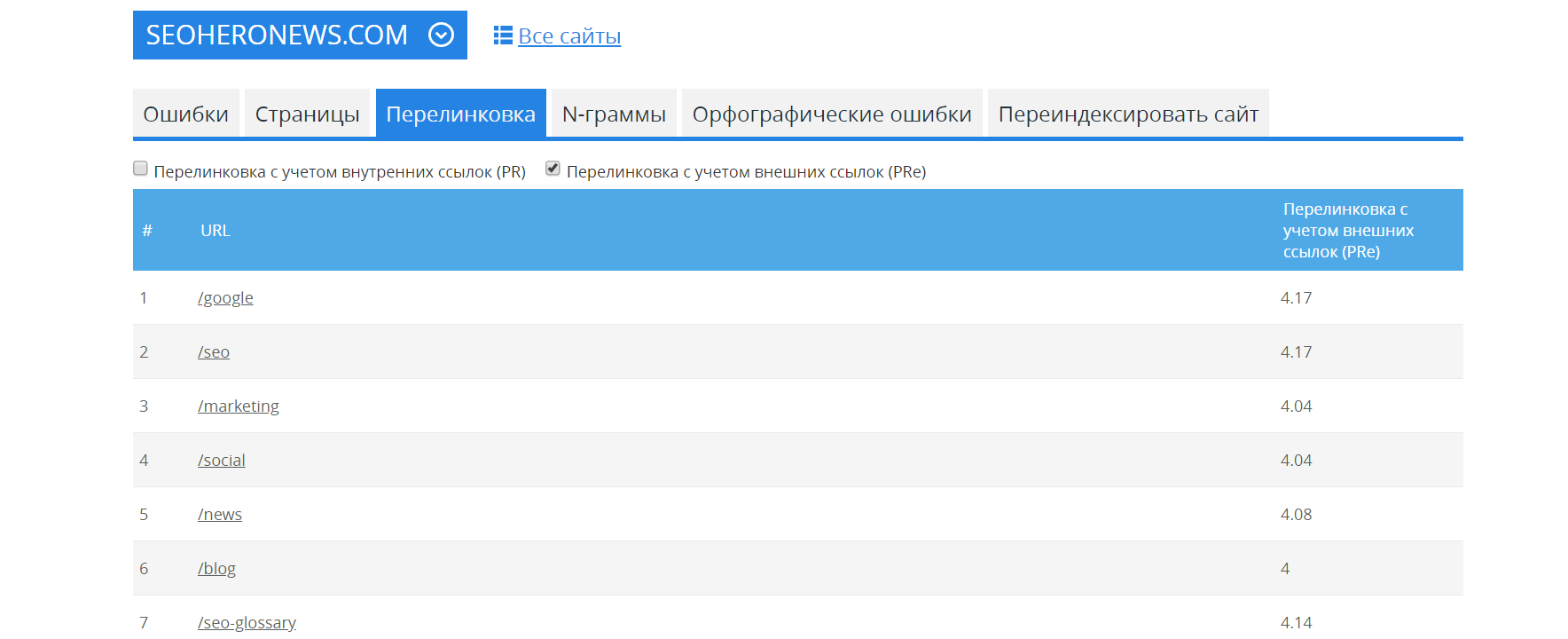
Ссылка на сервис — Аудит сайта.
Сервис бесплатный.
Рекомендованный материал в блоге MegaIndex по ссылке далее — Как бесплатно проверить оптимизацию сайта под мобильные устройства используя Google DevTools?
Выводы
IMPORTXML позволяет использовать роботов поисковой системы в своих целях. На больших объемах данных сканирование будет ограничено. Просто создайте новый документ с таблицей и IMPORTXML. Но для большинства задач лимитов хватает.
Функция IMPORTXML задается так:

Функция позволяет быстро парсить полезные данные, такие как списки.
Примеры задач:
- Парсинг списков дропов с открытых площадок для последующего анализа;
- Парсинг количества товаров в категории;
- Парсинг кодов ответа сервера;
- Парсинг количества страниц в индексе поисковой системы. Исключением является Google;
- Определять наличие текста на конкурентных страницах и длину в символах для текстового анализа.
Еще IMPORTXML позволяет узнать количество исходящих ссылок. Еще актуальные цены на конкурентных сайтах. И все бесплатно
Роботы парсят данные с любых сайтов, включая YouTube, Twitter и прочее.
Сервис бесплатный.
Данный инструмент позволяет быстро создавать отчеты под различные задачи.
Обсуждение
Ничего полезного...
For trekking in Nepal:
https://www.nepalhighlandtreks.com/
https://www.nepalhighlandtreks.com/upper-mustang-trip.html
Может подскажете как сделать это.
Сайт - https://dnipro-m.ua/
Буду очень благодарен!
С ID проблем не возникло, например "=importxml("https://finance.liga.net/currency";"//*[@id='biznes']/div/div[1]/div/div[5]/div[2]/table[1]/tbody/tr[1]/td[2]")" работает отлично, но некоторые сайты при копировании XPath дают данные в формате "/html/body/app-root/main/app-sidebar/main/div[2]/div[2]/div[11]/div[2]/span[2]/text()" и здесь как не пробую сделать формулу постоянно выдает ошибку.
Если есть решение буду весьма благодарен за подсказку.