

Полученные данные помогают конкурентам обогнать визави в поисковой выдаче.
Как скрыть ценную информацию от конкурентов? Разбираем самый эффективный метод, после выполнения которого конкуренты не смогут проанализировать ваш сайт.
1 — Целеполагание: зачем запрещать доступ к сайту роботам?
Сервисы конкурентной разведки позволяют выгрузить ценную информацию о вашем сайте. К полезной информации относятся: структура сайта, внешние ссылки, текстовое содержание и прочее.
Большинство предложений на рынке услуг по продвижению базируется на копировании стратегий лидеров поиска.
Работы состоят из простых шагов:
- Поиск конкурентов. Например, с использованием сервиса Поиск конкурентов от MegaIndex;
- Выгрузка ценных данных о конкурентных сайтах;
- Копирование решений.
Рекомендованный материал в блоге MegaIndex по ссылке — Поиск конкурентов по ключевым словам. Бесплатно. Как найти и зачем.
К ценным данным относятся:
- Внешние ссылки с частной сети сайтов;
- Структура сайта;
- Контент в части заголовков title, h1-h6, сниппетов и основное содержание страницы.
Данные по внешним ссылкам позволяет узнать сервис Внешние ссылки от MegaIndex.
Копирование успешных стратегий является действительно эффективным решением.
Скрыть сайт от сервисов конкурентной разведки можно разными способами.
Наименее эффективным является запрет в файле robots.txt.
Директива robots.txt является рекомендацией, а не правилом. Авторитетные сервисы такие как MegaIndex учитывают рекомендации. Но файл robots.txt не является гарантией от сканирования сайта другими сервисами.
Эффективным способом является запрет на уровне сервера. Пример кода размещено по ссылке — запрет сканирования сайта на уровне сервера.
Идея правильная, но способ не идеален.
2 — Проблема: Как роботы сканируют сайты в обход запретов?
При обращении к сайту на сервер передается запрос с информацией о клиенте. Обращения записываются в журнал посещений, так называемый файл называется logs. В файл logs сохраняется информация обо всех обращениях к сайту.
В каждой строке содержатся User-Agent, а также IP.
Поисковые системы представляются так:
- Googlebot;
- Yandex*. Например, Yandexbot, YandexCalendar, YandexMobileBot.
Сервисы представляются аналогично, к примеру MegaIndexBot.
Скрипт блокировки на уровне сервера отклоняет обращения согласно списку значений User-Agent.
Робот системы конкурентной разведки заблокирован. Но обойти защиту просто. Например, представиться краулером как Yandexbot или Googlebot. Определенные сервисы заявили публично, что начали сканировать сайты используя поддельные имена.
Что делать? Предлагаю решение, которое гарантированно закроет сайт от сканирования сервисами конкурентной разведки. Дополнительный эффект заключается в экономии трафика.
Принцип заключается в проверке робота на достоверность.
3 — Решение. Как закрыть сайт от сканирования системами конкурентной разведки
Метод базируется на использовании цепочки запросов к серверу доменных имен.
Порядок действий следующий.
Шаг 1. Робот поисковой системы обращается к сайту. В строке запроса указан. User-Agent поисковых систем Google и Яндекс. Выгружаем IP-адрес.
Шаг 2. По IP-адресу определяем хост, для этого выполняем обратный DNS-запрос.
Проверяем, принадлежит ли хост Яндексу или Google. Хосты всех роботов Google заканчиваются на googlebot.com или google.com. Хосты всех роботов Яндекса заканчиваются на yandex.ru, yandex.net или yandex.com. Если имя хоста имеет любое другое окончание, значит робот не принадлежит поисковой системе.

Шаг 3. Выполняем прямой DNS запрос на перевод хоста в IP, для этого выполняем прямой DNS-запрос. Получаем IP-адрес соответствующий имени хоста.
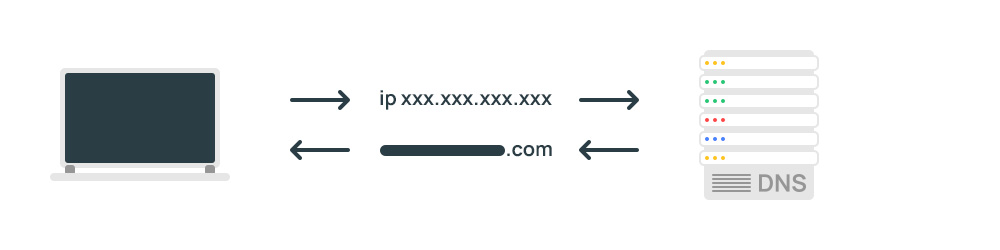
Шаг 4. Адрес должен совпадать с IP-адресом, использованным при обратном DNS запросе. Если IP-адреса не совпадают, значит полученное имя хоста поддельное.
В результате обращения к сайту от сервисов конкурентной разведки заблокированы. Для робота поисковой системы доступ к сайту открыт.
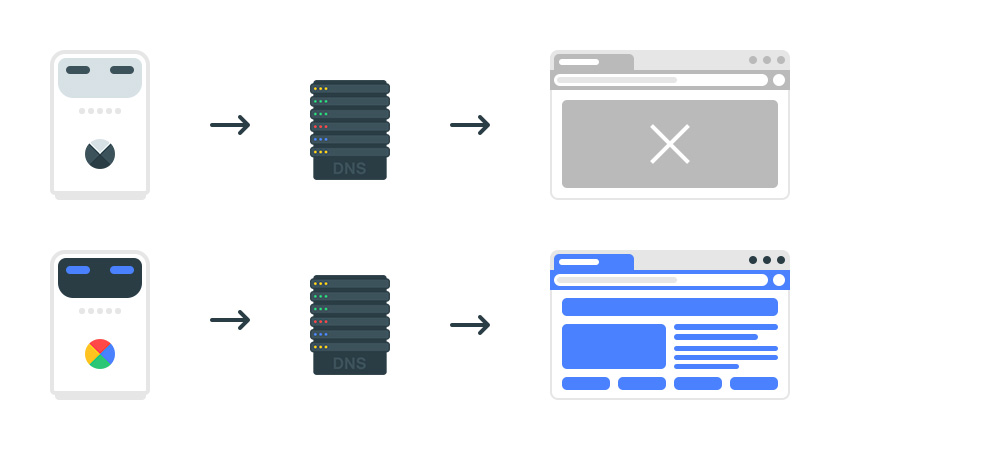
Как выполнить обратный запрос DNS?
Для реализации блокировки требуется скрипт, выполняющий описанный порядок действий. Методология реализуется на любом популярном языке.
Для понимания процесса показываю как проверить самому.
Например, через консоль Windows проверка выполняется через такие команды:
- nslookup;
- ping -a.
Запрос с использованием команды nslookup:
nslookup 89.108.117.218
Результат:
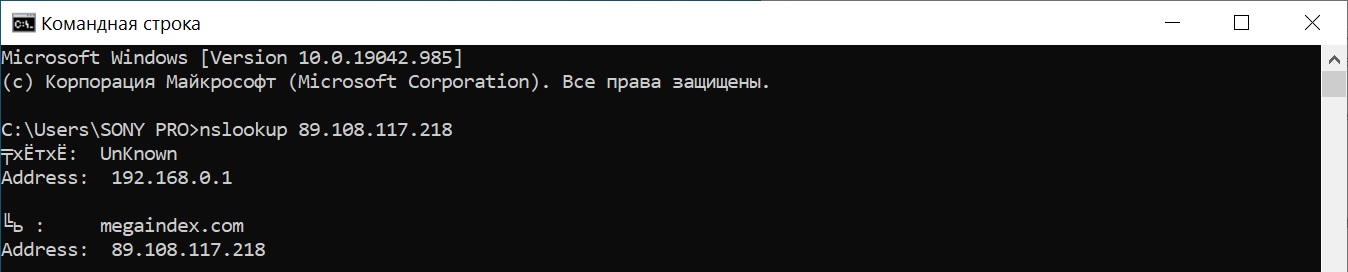
Запрос с использованием ping:
ping -a 89.108.117.218
Выводы
Часто под видом поисковых роботов к сайту обращаются системы по конкурентной разведке, спамеры.
Системы конкурентной разведки позволяют выявить ценные наработки по продвижению сайта.
Данные о выполненных работах по поисковой оптимизации позволяют конкурентам повторить успех.
Схема работы довольно простая:
- Найти лидеров поиска на базе данных о поисковой видимости сайтов;
- Провести техническую оптимизацию сайта;
- Скопировать успешные решения по сниппетам;
- Скопировать успешные решения по контенту;
- Скопировать успешные решения по внешним ссылкам;
- Внести дополнительную ценность на сайт.
Повторить стратегию лидера поиска просто, поэтому надо закрыть сайт от систем аналитики.
Есть расхожие простые способы. Например:
- Использовать запрет на уровне сервера. Пример кода размещен на indexoid;
- Запретить через robots.
Проблемы такие:
- Директивы robots исполняются не всеми роботами;
- Запрет на уровне сервера позволяет добиться принудительной блокировки. Но есть способ обойти защиту. Как? Блокировка проводится по признаку User-Agent. Решение по обходу блокировки заключается в подделке передаваемого значения.
Поисковые системы, включая Google и Яндекс, не публикуют списки адресов поисковых роботов.
Как же убедиться, что сайт сканирует именно робот поисковой системы?
Для проверки требуется выполнить обратный DNS запрос.
Если прямой DNS запрос позволяет получить IP по хосту, то обратный DNS запрос позволяет получить хоста по IP.
Система проверки с использованием DNS позволяет закрыть как главный сайт и сайты сателлиты от анализа любыми внешними сервисами.
Алгоритм проверки заключается в следующих действиях:
- Если к сайту обращается Googlebot, Yandex*, то выгрузить данные об IP;
- Выполнить обратный reverse DNS запрос. Убедиться, что в результате получено доменное имя принадлежащее поисковой системе. Для Яндекс — yandex.ru, yandex.net или yandex.com. Для Google — googlebot.com или google.com;
- Выполнить прямой DNS запрос для преобразования хоста в цифровой адрес.
- Проверить соответствие. IP должен совпадать с IP-адресом, использованным при обратном DNS запросе. Если IP-адреса не совпадают, значит что сайт сканирует не поисковая система, а хост поддельный.
Результат:
- Сайт доступен для обозначенных роботов поисковых систем;
- Сайт доступен для пользователей;
- Все страницы сайта закрыты от систем разведки.

В результате сервер не передает контент сторонним сервисам. Алгоритм позволяет сэкономить трафик и защитить сайт от сторонних роботов.
Настроек по DNS много. Если интересно узнавать больше об оптимизации сайта посредством DNS, напишите в комментариях.
Остались вопросы? Есть чем дополнить материал? Хотите узнать как отличить робота от пользователя? Напишите сообщение в комментариях.
Обсуждение
Думаю такой алгоритм правильнее:
1. Получаем IP обратившегося хоста.
2. Делаем реверс DNS.
3. Сверяем с белым списком и пропускаем или блочим.
Это как ставить механический замок с кнопками на подьезде. Формально войти может только тот кто знает комбинацию кнопок, на деле этот замок остановит только пьяного, который валяясь под дверью не может дотянуться до кнопок.
Любой маломальский грамотный технический специалист все подобные ограничения даже не замечает. Это характерно не только для решения вопросов сканирования. Это характерно для любы вопросов связанных с сетевой активностью.
Патология современных публичных сетей такова, что не дает никаких механизмов по дифференциации сетевых соединений. Как следствие, нет никакой возможности в ПО уровнем выше, реализовывать функционал который бы мог фильтровать "плохих" от "хороших".
Иными словами, если Ваш проект допускает анонимное соединение, то снять с Вас метрики не составляет никакого труда. Любой же эвристикой, которая пытается ранжировать клиента на основании частоты запросов, интенсивности и прочем можно клопов давить.
По очень простым причинам - не нужно даже иметь в личном пользовании сколько нибудь значимой распределенной сети для осуществления запросов из разных источников - они сейчас стоят сущие копейки в аренду. И часто вообще даются бесплатно в случае когда Вам нужен какой нибудь детский лимит по одному запросу с хоста. Не говоря уже о том, что те кто занимается решением похожих вопросов профессионально, имеют в своем распоряжении свои инструменты.