

Правила прописываются на основе протокола Robots Exclusion Protocol.
Google внес изменения в данный протокол. Например, теперь не поддерживается директива noindex.
Что еще изменяется и что делать?
Разберемся с вопросами далее.
Что произошло?
Поисковые оптимизаторы создают директивы для поисковых краулеров согласно правилам протокола Robots Exclusion Protocol. Такие директивы прописываются в файле robots.txt.
На протяжении 25 лет протокол REP являлся важным инструментом для поисковых оптимизаторов, так как позволял запрещать различным роботам доступ к некоторым страницам сайта.
Итак, используя директивы в файле robots.txt можно отсечь часть различных роботов, что приводит к снижению нагрузки на сайт. Как результат, у пользователей сайт открывается быстрее. Еще уменьшаются расходы на поддержку пропускного канала.
Поисковые системы такие как Yandex, Bing и Google следовали правилам из robots.txt.
Но протокол не был закреплен на официальном уровне.
Утверждает такие протоколы на официальном уровне организация под названием Internet Engineering Task Force (Инженерный совет интернета).
Ссылка на сайт — IETF.
Так как стандарт не был закреплен, то и правила обработки были не всегда понятными для всех.
Google решил задокументировать протокол REP и направил стандарт в соответствующую организацию на рассмотрение и регистрацию.
Такие действия призваны решить ряд целей:
- Расширить базу функциональных возможностей, чтобы можно было задавать более точные правила;
- Определить четкие стандарты, чтобы избежать различных спорных сценариев по использованию. В результате все причинно-следственные связи по использованию файла robots должны стать ясными для всех.
Что изменяется?
Список из наиболее существенных изменений:
- Теперь директивы можно использовать для любого URI. Например, теперь помимо HTTP/HTTPS правила можно применять к FTP или CoAP;
- Поисковые краулеры должны сканировать первые 512 килобайт файла. Роботы могут, но не обязаны сканировать весь файл если файл большой. Также роботы не обязаны сканировать весь файл, если соединение не стабильное;
- Размещенные в файле директивы подлежат кешированию. Делается так, чтобы не нагружать сервер запросами. По умолчанию кеширование проводится на срок не более чем 24 часа, чтобы дать возможность поисковому оптимизатору в приемлемые сроки обновлять файл. Значение по кешированию можно задавать самостоятельно используя директиву кеширования посредством заголовка Cache-Control;
- Если файл не доступен, то директивы продолжают работать. Спецификация предусматривает, что если файл robots.txt стал не доступен для поискового краулера, то правила описанные ранее будут продолжать действовать еще на протяжении длительного времени.
Далее были пересмотрены директивы, которые допускаются к использованию в файле robots.txt.
Правила, которые не опубликованы в стандарте, не будут поддерживаться Google.
В результате правило noindex больше не будет поддерживаться Google.
Поддержка отключается с 1 сентября 2019 года.
Еще был открыт исходный код парсера robots.txt. Данный парсер используется краулером Google для парсинга данных из robots.txt.
Ссылка на код — Google Robots.txt Parser and Matcher Library.
Если покопаться в коде, то можно найти информацию о том, что директива disallow будет работать, даже если ключевая фраза написана с опечаткой. Значит, указывать на такие ошибки в аудите сайта является бессмысленной затеей :)

Что делать?
Теперь для реализации noindex на практике следует использовать такие способы:
- Задавать noindex в мета-теге robots;
- Задавать noindex в HTTP заголовках.
Директива noindex является наиболее эффективным способом для удаления страниц из индекса.
Как задать директиву через HTTP заголовок? Требуется использовать заголовок X-Robots-Tag.
К примеру, если требуется запретить индексацию страницы indexoid, следует указать так:
X-Robots-Tag: noindex
Если есть только доступ к шаблону сайта, следует использовать мета-тег robots. Например, если для сайта 2yachts.com требуется запретить индексацию страниц, следует использовать такой код:
<meta name="googlebot" content="noindex">
Данный код указывает на запрет индексации для Google.
Если требуется запретить индексацию для разных ботов, а не только для Google, то в name следует использовать значение robots вместо googlebot.
Пример:
<meta name="robots" content="noindex">
Какой способ для удаления страниц из индекса поисковой системы является наиболее эффективным? Наиболее эффективным является манипуляция с кодом ответа. Если для страницы задать код ответа 404 или 410, то страница будет удалена из индекса поисковой системы.
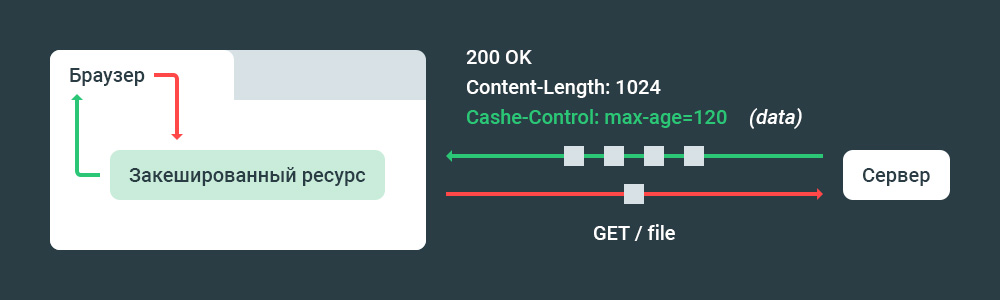
Как задать время на которое файл robots.txt будет кешироваться? Следует использовать заголовок Cache-Control.
Например:
Cache-Control: max-age=[секунды]
Директива задает период времени, в течение которого скачанный ответ может быть повторно использован.
Отсчет начинается с момента запроса.
max-age=[n секунд] означает, что ответ может быть закеширован и использован в течение n секунд.
Применив на практике вариант с кешированием процесс обработки файла будет выглядеть так:
Вопросы и ответы
Как проверить правильность настройки robots.txt?
Проверить директивы из файла robots.txt на валидность можно используя инструментарий для тестирования от Google.
Инструмент бесплатный.
Тест позволяет выявить проблемы в синтаксисе и сигнализирует на тему предупреждений, если такие есть.
Ссылка на инструмент — Google Robots.txt Tester.
И обратите внимание, что ссылки в файле robots.txt чувствительны к регистру.
Например такие ссылки считаются разными:
- ru.megaindex.com/SEO
- ru.megaindex.com/seo
Тест делает проверку как валидатор, поэтому на подобные нюансы не указывает.
Поддерживают ли другие поисковые системы noindex?
Yandex и Bing не поддерживают директиву в robots.txt.
Yandex рекомендует использовать noindex в метатеге robots или X-Robots-Tag.
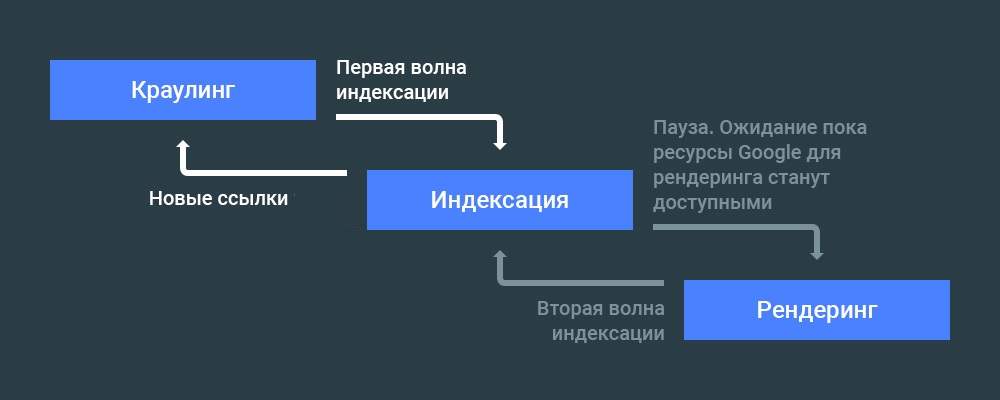
Нужно ли закрывать файлы CSS и JavaScript в robots?
Файлы стилей и скрипты закрывать не рекомендуется.
В поисковой системе используется рендеринг сайта. Рендеринг происходит перед ранжированием. Если запретить доступ к стилям и скриптам, поисковая система все равно проведет рендеринг сайта, но результат будет не корректным, что скажется на позициях в поисковой выдаче.
Весь процесс до старта алгоритма ранжирования выглядит так:
Рекомендованные материалы в блоге MegaIndex по теме краулинга страниц сайта поисковыми системами по ссылкам далее:
- Google обновил поисковый краулер. Что изменилось? Как это повлияет на ранжирование?;
- JavaScript и SEO.
Влияет ли запрет robots.txt на краулинговый бюджет?
На краулинговый бюджет влияют два главных фактора:
- Авторитетность доменного имени;
- Пропускная способность сервера сайта.
Авторитетность сайта зависит от качества внешней ссылочной массы.
Выгрузить и проанализировать список всех внешних ссылок по любому сайту можно используя сервис MegaIndex.
Ссылка на сервис — Внешние ссылки.
Еще в MegaIndex есть методы API, позволяющие обращаться к базе для выгрузки данных. Пример запроса к базе MegaIndex через API для сайта wixfy.com:
api.megaindex.com/backlinks?key=[ключ]&domain=wixfy.com&link_per_domain=1&offset=0&count=100&sort=link_rank&desc=1
Директивы в robots.txt не меняют значение по краулинговому бюджету.
Если посредством директивы Disallow в robots.txt исключается часть ненужных страниц, то краулинговый бюджет расходуется более рационально, что качественно влияет на индексацию сайта.
Как прописывать правила в robots.txt для поддоменов?
Директивы robots.txt распространяются только на верхний уровень хоста.
Например, если файл размещен на хосте smmnews.com, то все директивы будут применимы лишь для smmnews.com. Директивы не будут применены для www.smmnews.com и подобных хостов.
Указывать в файле robots.txt не имеет смысла.
Для указания директив на поддоменах файл robots.txt следует размещать на поддомене.
Выводы
25 лет директивы robots.txt использовались де-факто, но не были зафиксированы как стандарт. Теперь стандарт будет создан, а значит появится официальная документация и будет снята неопределенность по нюансам.
Например, теперь определен оптимальный размер файла — до 512 килобайт.
Если размер файла превышает пороговое значение, то директивы после 512 килобайт не учитываются.
Теперь протокол Robots Exclusion Protocol станет стандартом для интернета.
Вариант в виде черновика — Robots Exclusion Protocol.
Google больше не станет поддерживать директиву noindex, если ее использовать в файле robots.txt.
Для запрета индексации используйте заголовок или специальный мета-тег.
Новые сайты до запуска следует закрывать от индексации на уровне сервера.
Если сайт переведен на HTTPS, следует провести проверку на предмет доступности файла robots.txt по протоколу HTTPS. Если сайт переведен на HTTPS, но файл robots.txt доступен только по HTTP, то директивы для HTTPS страниц сайта действовать не будут.
Рекомендованный материал в блоге MegaIndex по теме перевода сайта на HTTPS по ссылке далее — Зачем и как перевести сайт на HTTPS бесплатно и без ошибок?.
Если говорить о практике, то в сухом остатке список действий следующий:
- Удалить из файла robots.txt директивы noindex;
- Разместить noindex в заголовке X-Robots-Tag или мета-теге с значением content="noindex";
- Если файл превышает 512 килобайт, то уменьшить размер файла за счет использование масок;
- Удалить из файла директивы на запрет индексации CSS и JavaScript файлов;
- Если требуется убрать страницу из индекса и запретить индексацию, следует использовать 404 или 410 код ответа;
- Задать время кеширования файла через Cache-Control.
Остались ли у вас вопросы, замечания или комментарии по теме robots.txt?
Интересно ли вам было бы узнать подробную информацию про краулинговый бюджет?
Обсуждение
Покажите пример, пожалуйста.
Пример - https://www.imd.org/robots.txt
Вроде и небыло ничего noindex в robots.txt указан.
Может быть Disallow больше не будет работать? Я что то запутался.
Disallow поддерживается.
Наверно они хотели сказать, чтобы страницу больше не индексировали поисковик одного Disallow недостаточно, нужно прописать на странице в meta noindex
Автор, я вас правильно понял?
Задавать noindex в мета-теге robots.txt;..."
Опечатка, насколько я понимаю
А так закрыть в robots.txt:
User-Agent: *
Disallow: /
Недостаточно разве?
Пользуемся новыми правилами через Meta.
Функцию "удалить страницу из поиска" не эффективна?
И еще, может подскажите ссылку на статью для грамотного составления роботс. Для каких роботов стоит настраивать отдельно, что стоит закрывать, что нет ...
Я понимаю, что для каждого сайта индивидуально, но в целом может есть информация.
Спасибо
Через meta name="googlebot" content="noindex" ?