Алгоритм Word2vec
Word2vec - технология, разработанная Google, для нахождения сематнических связей между словами.
Word2Vec включает в себя набор алгоритмов для расчета векторных представлений слов, предполагая, что слова, используемые в похожих контекстах, значат похожие вещи, т.е. семантически близки.
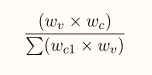
В числителе - близость слов контекста и целевого слова.
В знаменателе — близость всех других контекстов и целевого слова.
Технология Word2Vec использует два разных метода:
- CBOW - предсказание слова на основании близлежащих слов.
- Skip-gram – предсказание близлежащих слов на основании одного слова.
При расчете используются искусственные нейронные сети.
Во время обучения алгоритм формирует оптимальный вектор для каждого слова с помощью CBOW или skip-gram.
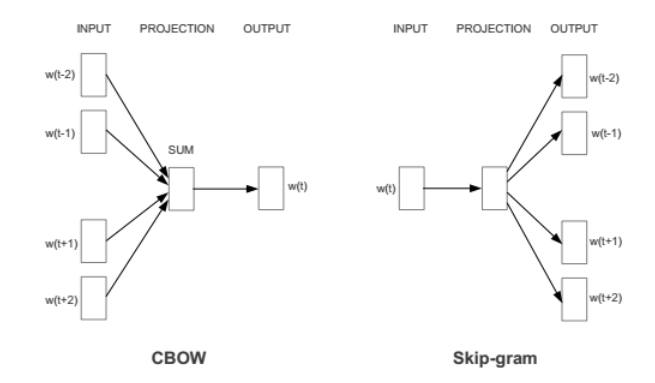
w(t) – данное слово
w(t-2), w(t-1) и т.д. – близлежащие слова
Метод представления слов в виде векторов используется для кластеризация слов и выявления их семантической близости, т.е. разделяет несвязанные слова и соединяет связанные, что помогает в задачах кластеризации и классификации текстов.
Как это работает?
- Читается корпус, и рассчитывается встречаемость каждого слова в корпусе.
- Массив слов сортируется по частоте и удаляются редкие слова.
- Строится дерево Хаффмана (для кодирования словаря — это значительно снижает вычислительную и временную сложность алгоритма).
- Из корпуса читается т.н. субпредложение (базовый элемент корпуса — предложение, абзац, статья) и проводится субсэмплирование (процесс изъятия наиболее частотных слов) из анализа.
- По субпредложению проходим окном (максимальная дистанция между текущим и предсказываемым словом в предложении).
- Применяется нейросеть прямого распространения с функцией активации иерархический софтмакс и/или негативное сэмплирование.
Рекомендуем провести оценку показателя Word2Vec в нашем приложении "Анализ текста".
Более подробно: https://ru.wikipedia.org/wiki/Word2vec
Рекомендуем посмотреть видео по теме.





