

На рынке распространяются разные SEO мифы про BERT.
- BERT применяется только для анализа поисковых запросов, и не применяется для анализа контента на странице;
- Алгоритм практически никак не влияет результаты поисковой выдачи.
А еще Yandex начал использовать алгоритм BERT. Зачем? Для каких целей?
Итак, есть следующие вопросы:
- Применяется ли BERT для анализа текстов на сайтах?
- Почему в поисковой выдаче Google не были замечены значимые флуктуации? Есть ли объяснение?
- BERT в Yandex.
Разберемся с всеми вопросами далее.
Миф 1: Используется ли BERT для анализа текста на сайтах?
Многие поисковые оптимизаторы до сих пор считают, что Google BERT применяется лишь для анализа интента поисковых запросов. Как пример, комментарий под статьей:
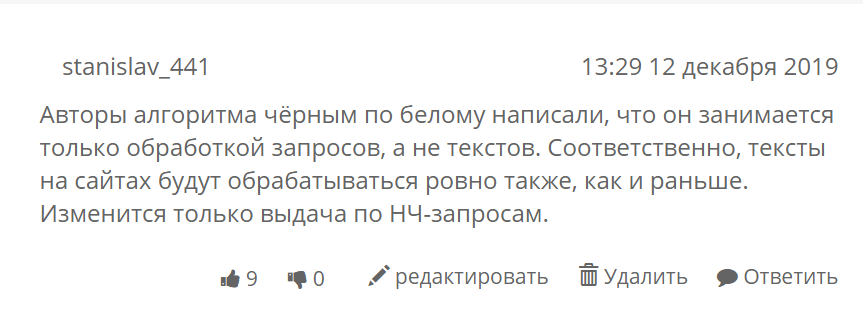
Ряд коллег поддержали данный комментарий. Некоторые вовсе писали, что все это бред. :) Спасибо за критику.
Да, действительно в анонсе черным по белому написано, что алгоритм применяется для анализа поисковых запросов. Приводятся примеры. И не написано, что BERT применяется еще и для анализа контента на сайтах.
Еще есть такое расхожее мнение, что BERT создан для улучшения поисковой выдачи по голосовому поиску.
Но отсутствие информации является недостаточным, чтобы делать утверждение о том, что BERT не применяется к контенту.
Мне логика лиц принимающих решения в Google понятна. Тем не менее, аргументы приводить не буду. Есть более простой способ разрушить данный миф. Несколько лет назад проводился мировой конкурс по SEO, по результатам которого я занял второе место. Обязательным условием было соблюдение правил Google, иначе участник исключался. В результате у меня остались контакты в Google. Я уточнил информацию по данной теме напрямую.
Yes, for both understanding queries, and for understanding the content.
Зафиксируем: Google использует новый алгоритм для анализа контента на страницах.

Далее разберемся с флуктуациями в поисковой выдаче.
Миф 2: Алгоритм практически никак не влияет на результаты поисковой выдачи
Ранее все текстовые алгоритмы были нацелены на анализ ключевых фраз. Главная цель нового алгоритма заключается в решении задачи по пониманию контекста.
Модели BERT могут анализировать не только отдельные слова, но и понимать контекст, в котором слова употребляются.
В результате технология способна значимо улучшить результаты поисковой выдачи. В поисковой системе так характеризуют новый алгоритм:
Крупнейший прорыв и один из самых грандиозных успехов за всю историю Google Поиска.
Многие сайты, которые были созданы под низкочастотные ключевые фразы должны были потерять позиции поисковой выдаче. Почему не были замечены значимые флуктуации? Есть причины.
Причина 1. Затраты на ресурсы. Модели Google настолько сложные, что для обработки требуемых данных пришлось впервые применять тензорные процессоры (TPU), созданные специально для машинного обучения нейронных сетей. BERT заточена под тензорные процессоры Google, поэтому из коробки умеет работать только с одной видеокартой.
Причина 2. Плохой претренинг на русском и других языках. На GitHub доступен исходный код на TensorFlow и даже предобученная универсальная модель BERT на 102 языка. Специалисты Yandex испытали данную модель. Оказалось, что универсальная модель на русских текстах показывала существенно меньшее качество, чем английская модель, бьющая рекорды на английских текстах (что, согласитесь, логично). На русских текстах она проигрывала внутренним моделям Yandex на DSSM. По данным Yandex на переобучение потребовался бы год.
Итак, BERT практически не влияет на результаты поисковой выдачи на русском, украинских и других языках ввиду технических и экономических причин. В перспективе ситуация изменится, а значит поисковому оптимизатору следует быть подготовленным. В западном сегменте ситуация иная.
Для каких целей BERT начал применяться в Yandex?
BERT в Yandex. Зачем Yandex начал использовать BERT?
Да. Yandex начал использовать BERT. Не для ранжирования. Алгоритм используется для решения таких задач:
- Поиска ошибок в новостях, а именно для поиска опечаток в заголовках новостей.
- Поиск устаревших заголовков.
Зачем искать опечатки в заголовках? Чтобы исключить новости с ошибками в заголовках из топа.

Комментарии экспертов на тему алгоритма BERT
Джейкоб Узкорейт, руководитель берлинской команды Google AI Brain:
В отличие от других прошедших претренинг языковых моделей, созданных посредством обработки нейросетями терабайтов текста, читаемого слева направо, модель BERT читает и справа налево, и одновременно слева направо, и обучается предсказывать, какие слова случайным образом были исключены из предложений. К примеру, BERT может принять на вход предложение вида «Джордж буш […] в Коннектикуте в 1946 году», и предсказать, какое именно слово скрыто в середине предложения (в данном случае, «родился»), обработав текст в обоих направлениях. «Эта двунаправленность заставляет нейросеть извлечь как можно больше информации из любого подмножества слов.
John Mueller, Webmaster Trends Analyst из Google:
I would primarily recommend taking a look at the blog post that we did around this particular change.
In particular, what we’re trying to do with these changes is to better understand text.
And on the other hand better understanding the text on a page.
The queries are not really something that you can influence that much as an SEO.
The text on the page is something that you can influence. Our recommendation there is essentially to write naturally.
What special attributes do we need to watch out for and that would allow use to better match the query that someone is asking us with your specific page.
So, if anything, there’s anything that you can do to kind of optimize for BERT, it’s essentially to make sure that your pages have natural text on them and that they’re not written in a way that.
Kind of like a normal human would be able to understand. So instead of stuffing keywords as much as possible, kind of write naturally.
Что будет изменяться в перспективе?
Раньше если по высокочастотным ключевым фразам конкуренция была высокой и для продвижения требовались большие инвестиции, то был альтернативный дешевый способ раскрутки страниц по низкочастотным ключевым фразам. Подобные ключевые фразы продвигались в ТОП за счет таких факторов:
- Техническая оптимизация продвигаемых страниц сайта;
- Поисковая оптимизация текста на страницах.
На таких сайтах суммарный объем трафика по низкочастотным ключевым фразам больше за объем трафика по всем иным ключевым фразам. BERT анализирует не только текст поисковых запросов, но и текст на страниц сайта. Значит данный способ больше эффективным не будет. Тем не менее, данный способ работает и сейчас, так как универсальная модель BERT не прошла хороший претренинг на текстах на русском языке. Но тренд указывает, что ситуация будет изменяться в перспективе.
По мере улучшения подобных поисковых алгоритмов, трафик из поисковой выдачи будет перетекать от мелких сайтов, заточенных по низкочастотные ключевые фразы, к крупным авторитетным сайтам.
Что делать на сайте сейчас?
Если есть сетки сайтов под привлечение трафика по низкочастотным запросам, то следует создавать еще и альтернативные сайты с уменьшенным объемом страниц.

На главных сайтах следует адаптировать формат текстов под текст для людей и расширить семантические ядра страниц. Как? Например так:
- Расширить страницы текстом, с вхождением дополнительных релевантных ключевых фраз из поисковой видимости;
- Анализировать поисковые запросы, по которым был привлечен трафик на сайт и добавлять релевантные фразы в контент;
- Добавлять в контент релевантные фразы из поисковых подсказок Google, Bing и Yandex. В данном источнике появляются низкочастотные фразы, которых нет в других системах;
- Анализировать логи внутреннего поиска и добавлять в контент найденные релевантные ключевые фразы.
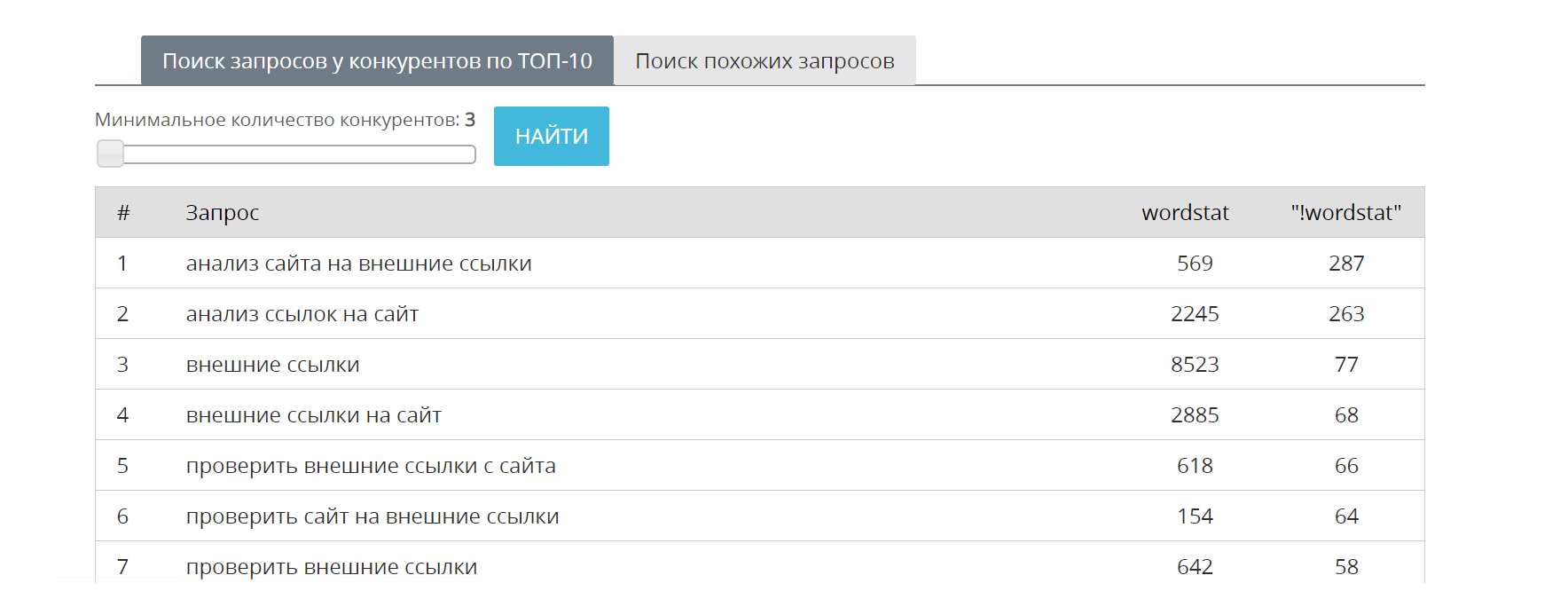
Как выгружать ключевые фразы сайтов из поисковой видимости? Самый простой способ заключается в выгрузке данных из базы MegaIndex.
Робот регулярно сканирует поисковую выдачу, собирает и обновляет списки ключевых фраз, по которым ранжируются сайты.
Ссылка на сервис — Поиск ключевых фраз на основе данных о поисковой видимости.
Пример отчета далее:
Рекомендованный материал в блоге MegaIndex по теме расширения списка ключевых фраз похожими по ссылке далее — Как находить дополнительные ключевые фразы, чтобы привлечь больше трафика?
Наглядный пример по использованию сервиса:
Выводы
У BERT такая архитектура нейросети, которая позволяет учитывать весь контекст сразу, включая другой конец предложения и причастный оборот где-нибудь в середине. И в этом её отличие от предыдущих модных архитектур, которые учитывали контекст. Например, у нейросети LSTM длина контекста — в лучшем случае десятки слов, а тут все 200.
Интеграция технологии BERT с поисковой системой Google проведена. BERT применяется к анализу поисковых запросов, и к анализу контента на страницах сайта. Качество улучшений поисковой выдачи зависит от языка. Следует оптимизировать тексты на страницах сайтах. Как? Использовать естественный язык в текстах. Расширять семантические ядра страниц сайта за счет добавления релевантных ключевых фраз и фрагментов текста. Еще имеет смысл начинать работу с альтернативными источниками трафика, такими например как YouTube.

Yandex применяет BERT для поиска проблемных заголовков. Следует учитывать данное нововведение при работе с новостным трафиком в рунете.
Рекомендованные материалы в блоге MegaIndex на тему алгоритма по ссылкам далее:
- Google BERT — новый поисковый алгоритм. Как изменится ранжирование и что делать сейчас?;
- SEO под низкочастотные (НЧ) запросы больше работать не будет? Google применил алгоритм BERT на все запросы.
Есть ли вопросы на тему Google BERT? Напишите в комментариях.
Обсуждение
Также можно пользоваться сервисами сбора поисковых подсказок, собирать подсказки и вопросы по продвигаемому ключевому запросу, внедряя их в текст.
Еще вариант – посмотреть семантику лидеров топа по нужному Вам запросу.
Ссылка на сервис - https://ru.megaindex.com/a/wordcluster?word=%D0%BF%D1%80%D0%BE%D0%B4%D0%B2%D0%B8%D0%B6%D0%B5%D0%BD%D0%B8%D0%B5+%D1%81%D0%B0%D0%B9%D1%82%D0%B0&type=1&from=264&min_urls=0