

Системы парсинга работают автоматически. В результате позиции продвигаемого сайта могут снижаться.
Как защититься от парсинга сайта?
Какие методы по защите наиболее эффективны? Разберемся с вопросами далее.
Новый эффективный способ защиты от парсинга сайта
С целью ограничения доступа к сайту можно использовать капчи. Главным недостатком данного способа считались неудобства, которые создавалиcь для реальных пользователей. Например, была необходимость ввода текста с картинки или разгадывание графики.

Google придумал как решить проблему с такими неудобствами. Решение заключается в анализе данных об активности пользователей.
Если обладать данными о трафике, то проверку можно проводить в фоновом режиме, без участия пользователя.

Итак, сейчас в сервисах Google используется новое решение по защите от ботов. Подобное решение доступно для всех пользователей.
reCAPTCHA является бесплатным сервисом, который позволяет защитить сайт от парсинга и спама.
Ссылка на сервис — reCAPTCHA.
Ссылка на документацию — Документация по reCAPTCHA.
На практике через Google reCAPTCHA API можно получить данные о том, является клиент роботом или нет.
По каждому из клиентов Google передает числовое значение по шкале от 0.1 до 0.9.
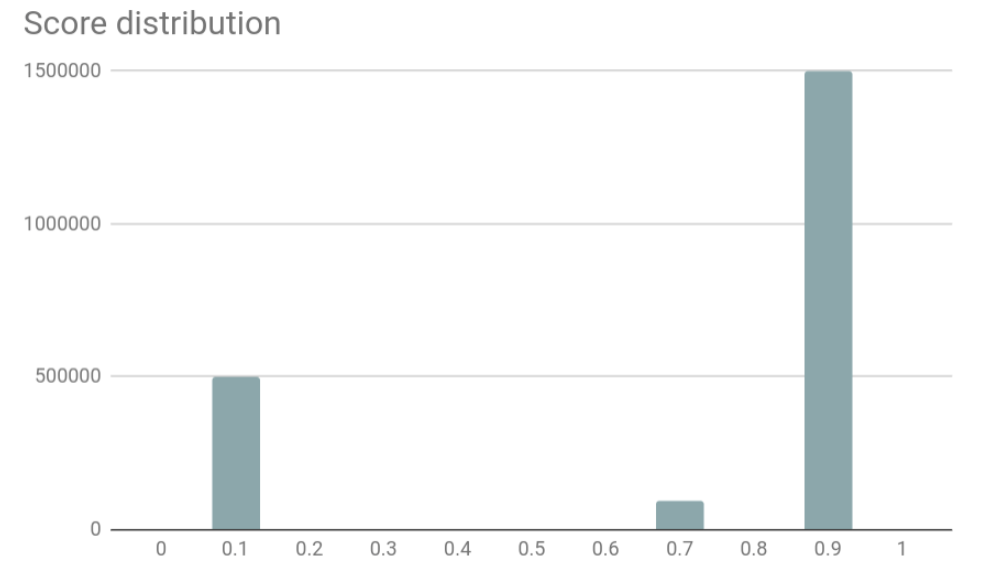
Примеры значений:
- 0.9. Означает, что клиент с высокой вероятностью является пользователем. При таких значениях никаких дополнительных проверок и ограничений на использование сайта создавать не следует;
- 0.3. Означает, что клиент скорее пользователь, нежели робот. Для клиентов с такими значениями имеет смысл иногда проводить дополнительную проверку. Например, проверку можно проводить во время подозрительной активности или при пиковой нагрузке на сервер сайта;
- 0.1. Означает, что клиент скорее робот, нежели пользователь.
На базе полученных значений следует выстраивать дальнейшую цепь действий.
При значении 0.3 имеет смысл не выводить рекламные блоки, чтобы не занижать значение параметра кликабельности.
Значение 0.1 является лишь поводом для того, чтобы присмотреться к клиенту. Нет смысла блокировать клиентов с таким значением. Такие значения могут получать реальные пользователи. Например, из практики было замечено что значение 0.1 получают клиенты Мегафона, оператора мобильной связи.
В идеале правильным решением будет создание процесса с дополнительной проверкой. Как лучше организовать процесс проверки? Например так:
- При 0.9 никаких дополнительных проверок проводить не следует;
- При 0.3 проводить проверки иногда;
- При 0.1 проводить проверки, например с использованием текстовой капчи.
После прохождения дополнительных проверок следует использовать cookies для сохранения результатов, иначе пользователям придется часто проходить проверки, что является не здравому смыслу.
Итак, на практике использование сервиса reCAPTCHA помогает убедиться в том, что посетитель сайта является реальным человеком.
Но при использовании мотивированного трафика проверку капчами можно обходить в реальном времени.
Например, такие сервисы как 2Captcha и ruCAPTCHA помогает обходить любые типы капч.
Для графической капчи стоимость составляет не более 44 рублей за 1000 решений.
В случае с reCAPTCHA стоимость составляет от 160 рублей за 1000 решений.
Ссылка на сервис ruCAPTCHA — ruCAPTCHA.
Ссылка на сервис 2captcha — 2captcha.
Еще один способ по защите от парсинга сайта — Ловушка для ботов
В качестве превентивной меры по защите от парсинга сайта следует использовать ловушки для ботов, так называемые honeypot.
Суть данного метода заключается в создании приманки для ботов, что впоследствии позволяет собрать список роботов, изучить стратегию злоумышленников и определить перечень средств, с помощью которых могут быть нанесены удары по серверам сайта. Далее специалисты в области безопасности разрабатывают стратегии снижению рисков при парсинге сайта или DDoS атаках.
На практике способ заключается в том, что на сайте размещается ссылка, по которой не будут переходить пользователи, но будут переходить боты.

К примеру, в качестве такой ссылки может быть прозрачная картинка размером 1 на 1 пиксель.

Анализ свойств IP-адреса
Еще для сегментации запросов на пользовательский трафик и обращения роботов можно использовать анализ свойств IP-адреса клиента.
Зачастую у роботов в свойстве type прописано значение hosting или business.
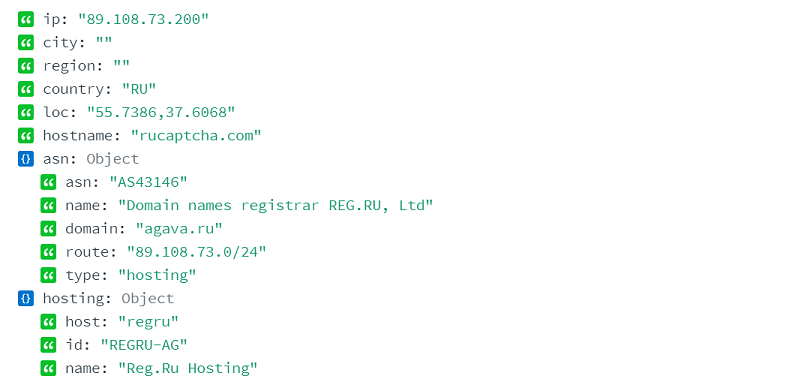
В случае с пользовательским трафиком, в свойствах IP в type обычно задано значение isp. Исключением являются случаи с использованием прокси.

Как результат можно собрать список роботов, чтобы в дальнейшем по требованию перекрывать доступ к сайту, например в таких случаях:
- Парсинг сайта;
- Увеличение нагрузки на сайт, которое превышает пропускную способность канала, что приводит к проблемам с загрузкой сайта;
- DDoS атака на сайт.
Но если для блокировки использовать весь список роботов, то на сайт не попадут краулеры поисковых систем и социальных сетей, которые подгружают с сайтов данные для предпросмотра ссылок.
Как выстроить систему так, чтобы были минимальные потери? Требуется найти решение для следующей задачи:
- Закрыть доступ к сайту для черных роботов;
- И оставить открытым доступ к сайту для белых роботов. К белым роботам могут относиться краулеры разных поисковых систем и социальных сетей.
При таком варианте доступ к сайту можно оставить открытым только для реальных пользователей и краулеров социальных сетей и поисковых систем.
Для решения задачи требуется провести анализ IP адресов, которые используют роботы. В результате весь список должен быть поделен на 2 списка:
- Белые роботы. В список должны попасть действительно белые роботы и роботы, которые с высокой вероятностью являются такими;
- Черные роботы.
Как создать белый список роботов? Для ответа на данный вопрос следует проанализировать большие объемы данных о роботах.
Менеджеры проектов регулярно решают подобные задачи. Если вдаваться в технические детали работы систем парсинга, то можно сделать выводы о характерных признаках белых роботов.
Признак следующий — у белых роботов есть PTR запись. У черных роботов значение в PTR записи встречаются реже.
PTR записи используются как инструмент для получения имени хоста (hostname) по IP-адресу.
Пример hostname:
Применять анализ следует только к трафику роботов, так как в случае с пользовательским трафиком PTR не используется в принципе.
Сервисы для защиты от парсинга сайтов
Одними из наиболее популярных сервисов по защите от парсинга являются CloudFlare и Distil Networks.
CloudFlare предоставляет возможности по защите сайтов на бесплатной основе, но есть и платные тарифы.
На бесплатном тарифе используется примитивный способ защиты.
При возрастании нагрузки на сайт сервис начинает выдавать посетителям страницу с капчей для прохождения проверки.
Подобное решение не является эффективным, так как создает неудобства для значимой части аудитории сайта.
Сервис представляет интерес в редких случаях. Например, если речь идет про такие сервисы как конструкторы сайтов или про создание сети PBN сайтов, то CloudFlare может быть эффективным решением.
В большинстве случаев все PBN сайты находятся на одном кластере или даже одном сервере. Доменные имена у всех сайтов разные. IP адреса разные за счет проксирования. В таком случае при использовании CloudFlare, если на любой из сайтов происходит DDoS атака, то перестает работать только один сайт, а не вся сеть.
Рекомендованные материалы в блоге MegaIndex по теме private blog networks по ссылкам далее:
- Как построить частную сеть сайтов для SEO. PBN сайты в поисковой оптимизации;
- Чем чаще домен освобождался и менялся его владелец, тем хуже работают ссылки с него — верно ли утверждение;
- Будет ли ссылка передавать вес, если на сайте нет трафика;
- Обнуляется ли вес ссылочного профиля домена спустя год после освобождения;
- Нужно ли ждать перед тем, как размещать исходящие ссылки с PBN сайтов и сателлитов;
- Правила линкбилдинга. Секреты линкбилдинга.
Для проектов с большими бюджетами рекомендуется использовать системы на основе Google reCAPTCHA и анализа роботов.
Крупные западные коммерческие сайты используют решение Distil Networks. Сервис Distil Networks является платным решением, но и платные решения не способны защитить сайт наверняка. В принципе такие сервисы лишь помогают увеличить затраты на парсинг или DDoS атаку. Навредить сайту остается возможным, но затраты на такое мероприятие для атакующей стороны возрастают.
Вопросы и ответы
Что такое парсинг сайта?
Парсингом сайта называется комплекс мер по извлечению данных с сайта. Впоследствии скопированный контент может использоваться для разных целей, например для продвижения иных сайтов или аналитики.
Как закрыть сайт от парсинга сервисами
Закрыть сайт от конкурентной разведки можно используй скрипт с сайта indexoid.
Пример директив сервера для файла htaccess на запрет:
Options FollowSymLinks ExecCGI
RewriteEngine On
RewriteBase /
RewriteCond %{REQUEST_FILENAME} !-f
RewriteCond %{REQUEST_FILENAME} !-d
RewriteRule ^[^4]* /404 [L,S=4000]
RewriteEngine on
RewriteCond %{HTTP_USER_AGENT} ".*AhrefsBot.*" [OR]
RewriteCond %{HTTP_USER_AGENT} ".*MJ12bot.*" [OR]
RewriteCond %{HTTP_USER_AGENT} ".*rogerBot.*" [OR]
RewriteCond %{HTTP_USER_AGENT} ".*MegaIndex\.ru/2\.0.*" [OR]
RewriteCond %{HTTP_USER_AGENT} ".*YandexBot.*" [OR]
RewriteCond %{HTTP_USER_AGENT} ".*ia_archiver.*" [OR]
RewriteCond %{HTTP_USER_AGENT} ".*bingbot.*" [OR]
RewriteCond %{HTTP_USER_AGENT} ".*Baiduspider.*" [OR]
RewriteCond %{HTTP_USER_AGENT} ".*archive\.org_bot.*" [OR]
RewriteCond %{HTTP_USER_AGENT} ".*BLEXBot.*" [OR]
RewriteCond %{HTTP_USER_AGENT} ".*LinkpadBot.*" [OR]
RewriteCond %{HTTP_USER_AGENT} ".*spbot.*" [OR]
RewriteCond %{HTTP_USER_AGENT} ".*Serpstatbot.*"
RewriteRule ".*" "-" [F]Для каких целей применяется парсинг сайтов?
Парсинг сайтов применяется для целей разного характера. Например:
- Копирование статей для размещения на конкурентных сайтах;
- Копирование отзывов;
- Анализ данных;
- Мониторинг цен;
- Сравнение цен;
- Агрегация данных для создания каталогов;
- Анализ изменений на сайте;
- Управление онлайн-репутацией в интернете;
- Копирование части содержания, например титров;
- Мониторинг новостных потоков;
- Копирование данных о прогнозе погоды;
- Прочее.
Еще роботы используются для создания трудностей в аналитике при обработке данных. К примеру, боты могут сканировать сайт, добавлять товары в корзины и так далее. В результате аналитика данных сильно затрудняется, системы подсказок работают не верно, а в базе накапливаются ненужные данные.
Законно ли использовать парсинг сайтов?
В большинстве стран никаких законов в отношении парсинга нет.
Но на разных территориях встречаются разные законы в отношении копирования контента. Например, если сайт принадлежит компании, которая зарегистрирована как юридическое лицо в штатах, то есть ряд законов, используя которые можно защититься от парсинга контента.
Например:
- Закон об авторском праве (Copyright infringement);
- Закон о компьютерном мошенничестве и злоупотреблениях (CFAA);
- Использования защиты на движимое имущество, так называемый Trespass to chattels.
Какие еще есть способы защиты от парсинга?
На большинстве сайтов размещается страница с Правилами использования сайта/Terms of use. В данном документе можно написать о запрете на копирование данных с сайта. Но правовой статус такого заявления не ясен.
Дополнительные способы защиты:
- Блокировка IP-адреса по списку или на основе таких критериев, как геолокация и/или черного списка DNS. Это также заблокирует весь просмотр с этого адреса;
- Блокировка по значению, указанному в строке user agent;
- Блокировка по значению, указанному в PTR записи;
- Парсеры могут быть заблокированы путем анализа клиента на получение избыточного трафика;
- Использование файла robots;
- Система анализа поведения пользователя для вычисления роботов с использованием таких данных: движение курсора, координаты нажатия на кнопки и прочее;
- Обфусцирование стилей;
- Динамическое изменение имен классов и кода сайта, без изменения результата для пользователя. Например, изменение стилей и верстки страницы.
Еще есть вариант использовать черные списки DNS, называемые еще как Domain Name System-based Blackhole List (DNSBL) или DNS Real-time Blackhole List (DNSRBL).
При использовании DNS black list происходит следующее:
- Сервер сайта устанавливает соединение с DNSBL;
- Система проверяет наличие в базе IP-адреса клиента, от которого пришел запрос на сайт;
- При положительном ответе считается, что происходит попытка парсинга или DDoS;
- Сервер отправителя получает ошибку 500, то есть отказ на запрашиваемые данные.
Выводы
Итак, конкуренты могут копировать контент с продвигаемого сайта. Для автоматического копирования контента достаточно настроить процесс сканирования, извлечения и публикации данных.
От парсеров следует защищаться по ряду причин. Например:
- Если речь про сервисы и облачные решения, то парсеры могут копировать данные с сайта и предоставлять их пользователям от имени иного бренда;
- Если речь про сайт информационного плана, то весь скопированный и размещенный в сети контент может быть проиндексирован поисковыми системами. В результате оригинальный источник будет терять трафик.
Что следует сделать для того, чтобы защититься от подобного копирования? Для защиты сайта от парсинга используйте способы приведенные выше. Например:
- Идентифицируйте роботов на основе данных о трафике, к примеру используя Google reCAPTCHA;
- Создайте белый и черный списки роботов;
- Настройте систему анализа и блокировки роботов.
Подобные действия могут быть автоматизированы.
Итак, парсеры можно заблокировать с помощью проверок на основе капч и аналитике трафика.
Результат следующий:
- Защита от парсинга сайта;
- Снижение нагрузки на сервер сайта. Увеличение скорости загрузки страниц;
- Защита от спама, который роботы создают для усложнения выполнения работ по аналитике;
- Блокировка спама в комментариях;
- Защита от анализа сайта злоумышленниками с использованием роботов;
- Защита от подбора паролей;
- Защита от сервисов конкурентной разведки;
- Защита от анализа сайта роботами на предмет возможности XSS и SQL инъекций.
Если речь идет про парсинг цен с сайта, то для таких ботов можно отдавать те цены, которые создаст генератор случайных чисел.
Что сделать, если контент уже скопирован? Если контент уже скопирован, то есть варианты удалить контент или извлечь пользу из копии. Рекомендуемые материалы в блоге MegaIndex по ссылкам далее:
- Как удалить страницы конкурентов из поисковой выдачи, если на них размещен скопированный контент? Что такое DMCA?;
- Как извлечь пользу, если контент скопировали? Как защитить контент от копирования на уровне сервера?
Итак, если использовать приведенные выше советы по проверке трафика при помощи капч, то на практике с различными неудобствами столкнется лишь часть аудитории, так как анализ рисков происходит в фоновом режиме.
Цена таких мероприятий как парсинг и DDoS атаки будет значимо увеличена.
При этом использование сервиса Google reCAPTCHA является бесплатным.
Защититься полностью от парсинга сайтов или DDoS невозможно, но можно снизить нагрузку на сайт и отбить большинство атак.
Остались ли у вас вопросы, замечания или комментарии по теме защиты сайтов от парсинга?
Обсуждение
ну хорошая защита, че.
Простое дешевое решение которое банит ip адреса парсеров отдавая им 403 ошибку. Полезно добавить нужные ip в белый список. Особенно актуально если парсеры любят укладывать вашу vps.
вообщем не надо параною наводить кому надо тот спарсит а такими способами навредить можете себе больше
Капча? Антикапча стоит недорого, но юзеры вас за капчу на каждой странице прибьют, ведь часто у многих юзеров один айпи, они под натом, ходят с мобильных сетей - вы, вообще, себе враг, что ли?
Юзерагенты? А рандом не хотите ли?
Ханипот? Ну так пока "ваши специалисты" будут вырабатывать стратегию, просто берется другая впс за два бакса и всё заново :D
Если хотите от парсинга защититься, единственный нормальный способ - конфигурить сервер таким образом, чтобы он отсекал соединения при большом числе запросов за определенный интервал времени. Так парсинг затягивается, но возможен - проксики.
Самая крутая защита - у яндекс-сервисов. Но и их парсят. Так что, не парьтесь.
Really?
2) встретил полезных парсеров-плагиатчиков, создающие у себя контент со ссылкой на наш сайт -- т.е. прирост ссылочной массы.
3) если ли у Вас статистика по ссылке-ловушке - каков % ботов на сайтах? "Роботность" Я-Метрики кажется не адекватной. Согласны?
4) боты сайта ... безобидны, если не входят по ... нашей рекламе. Есть ли статистика %% ботов в контексте и таркетинге?
да и не любой текст легко конвертировать обратно, в противном случае в капче не было смысла, не много фантазии и это серьёзно усложнит задачу парсерам и не будет мешать пользователям