

Что меняется? Как работает алгоритм? Как подготовить сайт к изменениям?
Стараемся разъяснить понятным языком.
Yet Another Transformer with Improvements — Новая технология анализа текста
Что произошло? Яндекс официально заявил о внедрении нейросетевой архитектуры Yet Another Transformer with Improvements для ранжирования результатов поисковой выдачи.
Благодаря технологии поиск Яндекса научился лучше оценивать смысловую связь между запросами пользователей и содержанием документов.
Изменения настолько существенные, что по мнению специалистов Яндекса, это наиболее значимое событие для поисковой системы за последние 10 лет, то бишь со времен запуска Матрикснета.
Анонс алгоритма на видео. Про обновление в поисковой системе с 56:41.
Технология дорогая. Реализация на практике требует множество GPU карточек, которые физически связаны через шину в одну плату. Сервера размещаются очень близко в стойках. Между собой сервера связаны сетью.
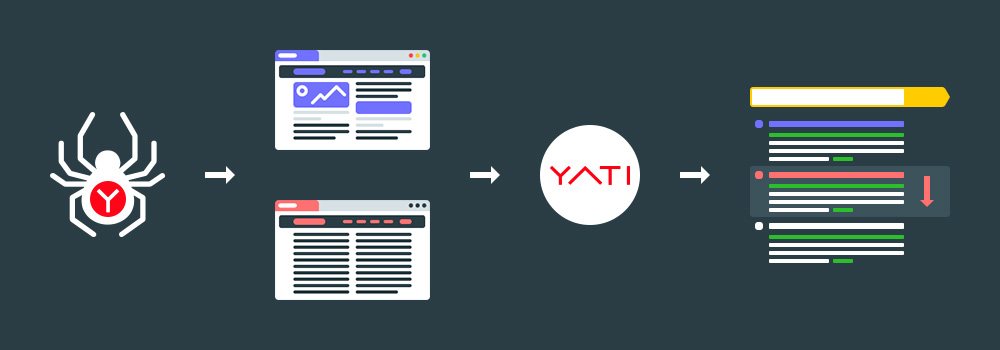
YATI выглядит так:

Как работает? Сначала опишем кратко, а далее разъясним в подробностях.
Для обучения на вход в трансформеры подаются поисковые запросы и тексты документов, которые открывали пользователи поиска.
В Яндексе есть понятие эталон документа. Как появились эталоны? Асессоры используя сложную шкалу оценки проводили анализ текстов на предмет релевантности запросам.
В результате эталоном выступает документ, который прошел экспертную разметку.
Эталоны подаются на вход в систему трансформеров.

Далее инженеры обучили трансформер угадывать экспертную оценку.
Так трансформеры учатся ранжировать страницы по всем ключевым фразам.
По завершению обучения провели анализ на предмет качества поиска.
Например, отключения учета внешних ссылок приводило к значимому снижению качества поиска.
Результаты показали, что технология дала рекордный уровень в качестве поиска.
Далее система начинает работать с поисковой выдачей.
Далее разберемся с вопросами в деталях.
Как работал поиск раньше?
Задача поиска заключается в оценке смысловой связи между поисковым запросом и документом из интернета.
Для решения задачи требуется алгоритм предсказания, содержит ли документ ответ на запрос пользователя. Иначе говоря, есть ли на странице релевантная запросу информация.
Поисковый алгоритм оперирует ключевыми словами из запроса и текста документа чисто математически. Например, алгоритмически легко посчитать число совпадающих слов в запросе и документе или длину самой длинной подстроки из запроса, которая присутствует и в документе.
Также легко воспользоваться накопленными данными поиска о поведенческих факторах на выдаче и достать из заранее подготовленной таблицы сведения о количестве кликов. Если значение кликов высокое, то значит документ релевантен ключевой фразе.
Каждый такой расчёт приносит полезную информацию о наличии семантической связи и эффективен на практике.
Поэтому следует оптимизировать сниппеты. Как улучшить привлекательность заголовка? Провести анализ конкурентной среды, чтобы найти наиболее удачные идеи для последующей реализации. К примеру, используя сервис MegaIndex.
Ссылка на сервис — Анализ сниппетов.
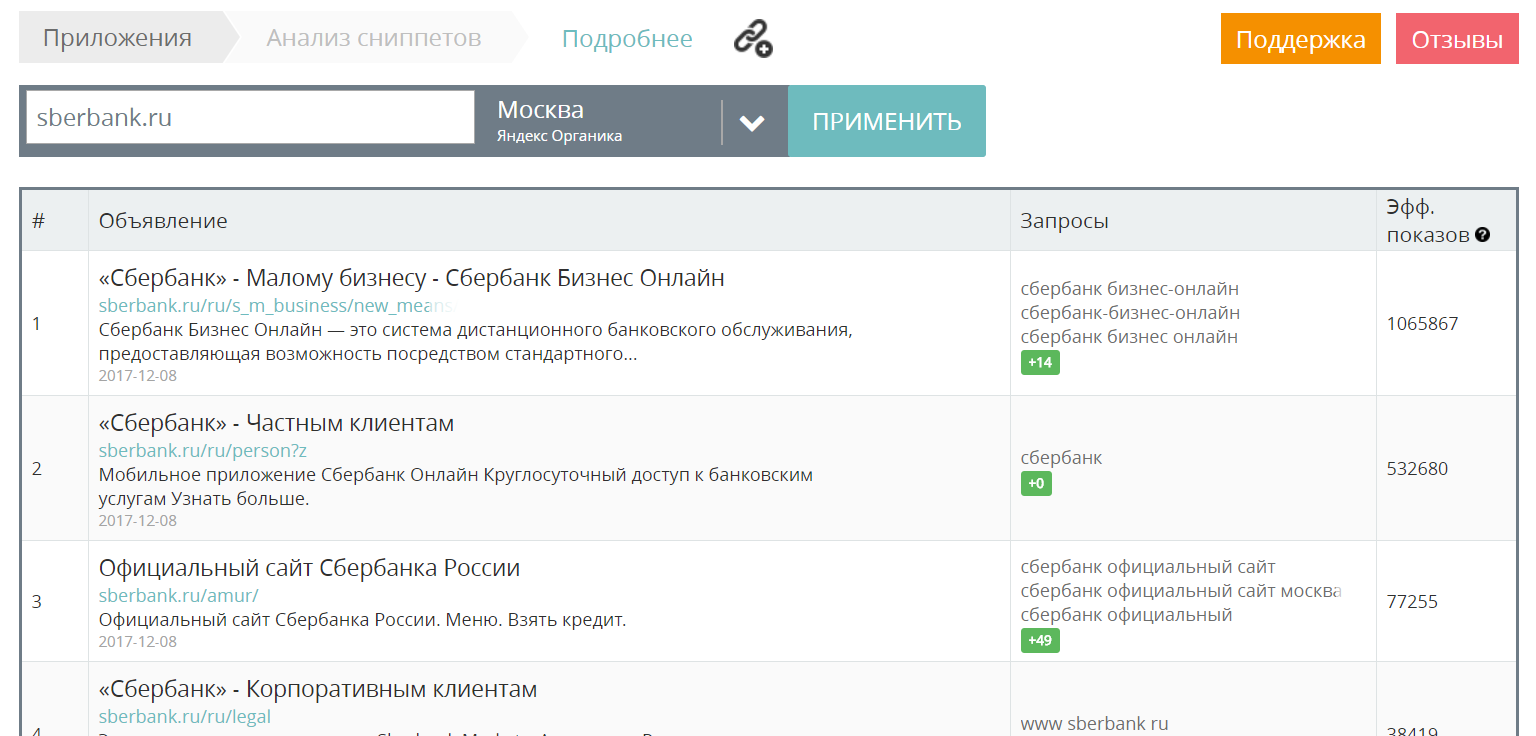
В поисковой системы реализованы различные эвристические алгоритмы. Например, только способов посчитать общие слова запроса и документа было предложено и внедрено несколько десятков.
Пример алгоритма:
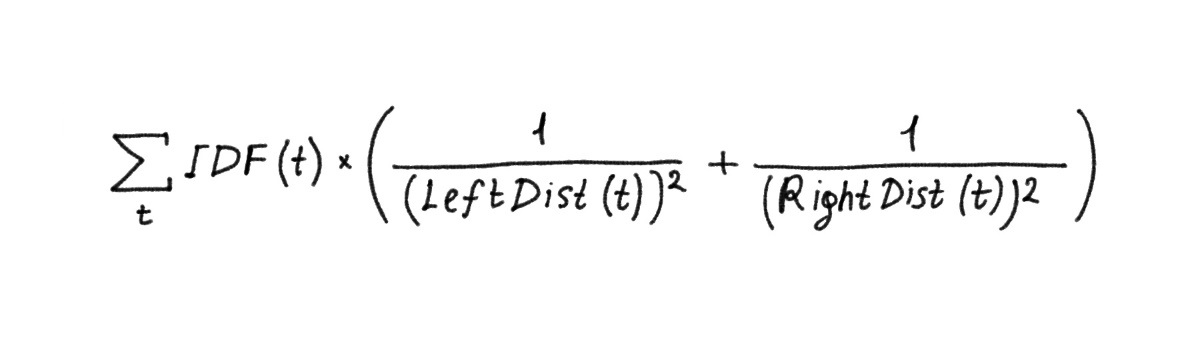
t — вхождение ключевого слова из запроса в документ.
Каждому t присваивается вес с учетом частотности слова в корпусе и расстояний до ближайших вхождений других слов запроса в документ слева LeftDist и справа RightDist по тексту.
Затем полученные значения суммируются по всем найденным на странице ключевым словам.
Каждый такой алгоритм позволял получить минимальный, но статистически значимый прирост качества модели, то есть чуть приблизить самую смысловую связь запроса и страницы.
Следующим шагом было расширение исходного поискового запроса. Подход такой:
- Слова из запроса можно расширить близкими им по смыслу словами или фразами;
- Вместо исходного запроса пользователя можно взять другой, который сформулирован иначе, но выражает схожую информационную потребность.
Например:
отдых на северном ледовитом океане
Близкие по смыслу фразы:
путешествие по северному ледовитому океану можно ли купаться в баренцевом море летом
Как поисковая система находит такие запросы? Способы разные. Например, использование логов запросов.
Похожий ключевые фразы можно использовать во всех эвристических расчётах сразу. Достаточно взять уже готовый алгоритм и заменить в нем один текст запроса на другой.
Аналогично запросам можно расширять и семантику документа, собирая для него альтернативные тексты, которые в Яндексе называют словом стримы.
Например, в стрим страницы входят все тексты входящих ссылок или тексты запросов в поиск, по которым пользователи часто выбирают конкретную страницу на выдаче.
Стримы можно использовать в любом готовом эвристическом алгоритме, используя вместо исходного текста документа.
Расширения и стримы являются примером дополнительных контентных признаков, которые поиск умеет ассоциировать с запросом и документом.
Большая часть таких алгоритмов утратили актуальность из-за спама, но сами расширения и стримы продолжают использоваться, только теперь уже в качестве входов для нейронных сетей.
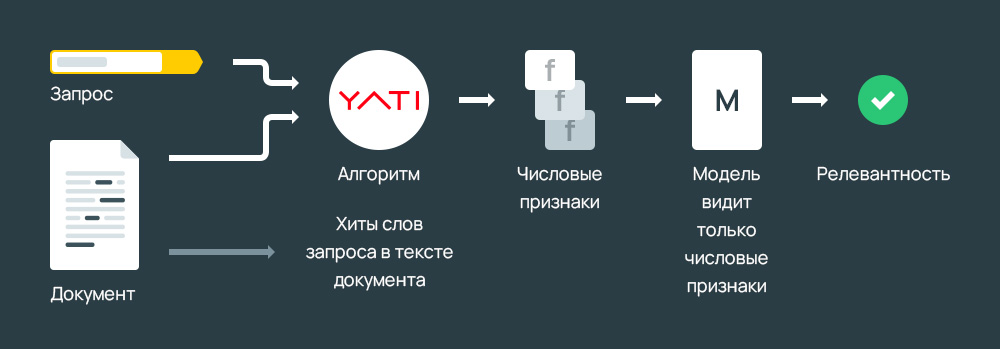
Как работает Яндекс YATI?
Факторы подаются на вход одной итоговой модели. Для обучения модели используется открытая реализация алгоритма GBDT (Gradient Boosting Decision Trees) — CatBoost.
Схема вычисления релевантности выглядит так:
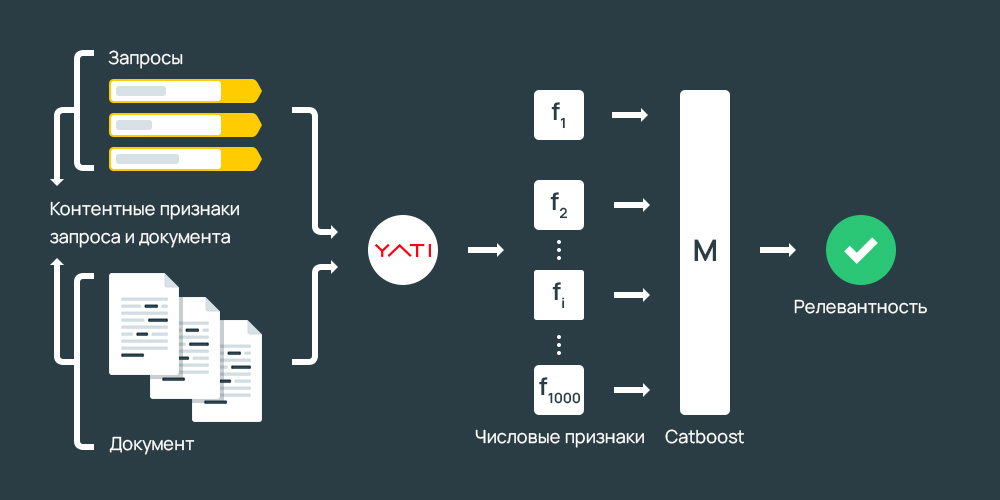
Описанные выше способы расчета приносят полезную информацию о наличии семантической связи, но не опираются на смысловое понимание текста.
Нейросети в ранжировании
Развитие алгоритмов ранжирования заключается в решении задачи по приближению семантической связи запроса и страницы сайта.
Схема с нейросетями изначально работала так:
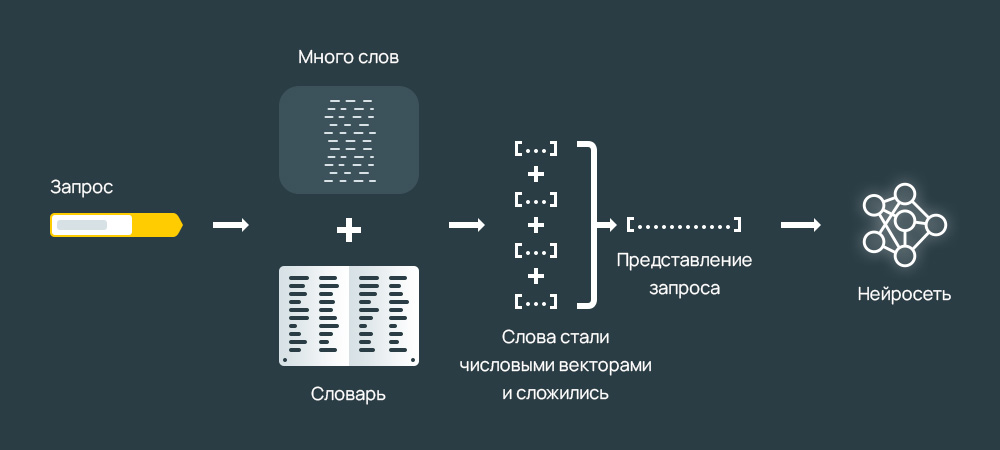
- Каждое слово превращалось в вектор;
- Вектора суммируются в один, который и используется как представление всего текста. Взаимный порядок слов при этом теряется или учитывается лишь частично с помощью специальных технических трюков. Кроме того, размер «словаря» у такой сети ограничен; неизвестное слово в лучшем случае удаётся разбить на частотные сочетания букв (например, на триграммы) в надежде сохранить хотя бы часть смысла;
- Вектор мешка слов затем пропускается через несколько плотных слоёв нейронов, на выходе которых образуется семантический вектор (иначе эмбеддинг, от англ. embedding, вложение; имеется в виду, что исходный объект-текст вкладывается в n-мерное пространство семантических векторов).
Замечательная особенность такого вектора в том, что он позволяет приближать сложные смысловые свойства текста с помощью сравнительно простых математических операций. Например, чтобы оценить смысловую связь запроса и документа, можно каждый из них сначала превратить в отдельный вектор, а затем вектора скалярно перемножить друг на друга или посчитать косинусное расстояние.
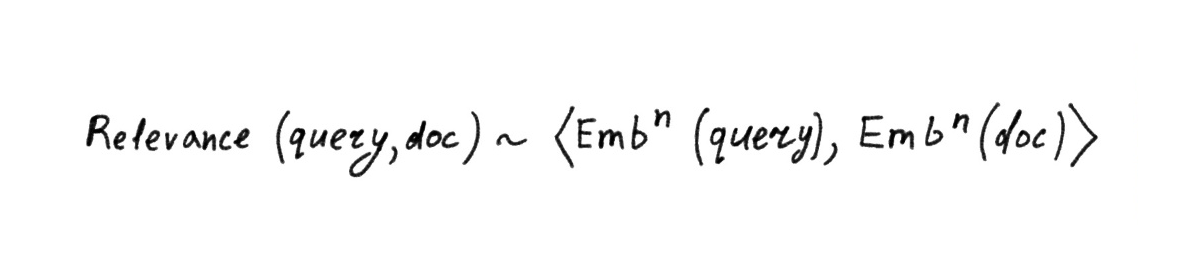
Нейронная сеть обучается приближать смысловую связь между запросом и документом на миллиардах обучающих примеров.
В качестве таргета (то есть целевого, истинного значения релевантности) используются предпочтения пользователей, которые можно определить по логам поиска. Точнее, можно предположить, что определённый шаблон поведения пользователя хорошо коррелирует с наличием (или, что не менее важно, с отсутствием) смысловой связи между запросом и показанным по нему документом, и собрать на его основе вариант таргета для обучения.
Если в качестве положительного примера обычно подходит документ с кликом по запросу, то найти хороший отрицательный пример гораздо труднее.
Например, оказывается, что почти бесполезно брать в качестве отрицательных документы, для которых был показ, но не было клика по запросу.
Ограничивающее свойство такой сети: весь входной текст с самого начала представляется одним вектором ограниченного размера, который должен полностью описывать смысл.
Однако реальный текст обладает сложной структурой. Размер может сильно меняться, а смысловое содержание может быть очень разнородным. Каждое слово и предложение обладают своим особым контекстом и добавляют свою часть содержания, при этом разные части текста документа могут быть в разной степени связаны с запросом пользователя. Поэтому простая нейронная сеть может дать лишь очень грубое приближение реальной семантики, которое в основном работает для коротких текстов.
Тем не менее тестирование показало, что качество поиска все же улучшается. Плотные feed-forward-сети легли в основу двух крупных алгоритмов Палех и Королев. Ключевыми вопросами при решении задачи были:
- На какой кликовый таргет учить?
- Какие данные и в каком виде подавать на вход?
Нейронная сеть, сначала обученная на миллиардах переформулировок, а затем дообученная на сильно меньшем количестве экспертных оценок, заметно улучшает качество ранжирования.
Характерный пример применения подхода transfer learning:
Модель сначала обучается решать более простую или более общую задачу на большой выборке (этот этап также называют предварительным обучением или предобучением, англ. pre-tain), а затем быстро адаптируется под конкретную задачу уже на сильно меньшем числе примеров (этот этап называют дообучением или настройкой, англ. fine-tune).
В случае простых feed-forward-сетей transfer learning уже приносит пользу, но наибольшего эффекта метод достигает с появлением архитектур следующего поколения.
Нейросети-трансформеры
Следующий уровень развития заключается в применении трансформеров. В сетях с архитектурой трансформеров каждый элемент текста:
- Представляется отдельным вектором;
- Обрабатывается по отдельности;
- Сохраняет при этом своё положение.
Элементом может быть отдельное слово, знак пунктуации или частотная последовательность символов, например byte pair encoding.
Важно, что сеть также включает механизм внимания, который позволяет при вычислениях концентрироваться на разных фрагментах входного текста.
Значит, сеть может выделить часть страницы интернет-магазина, в которой речь идёт именно о нужном пользователю товаре. Остальные части тоже могут быть учтены, но влияние на результат будет меньше.
Иными словами, механизм внимания позволяет оценивать в формате запрос — часть страницы.
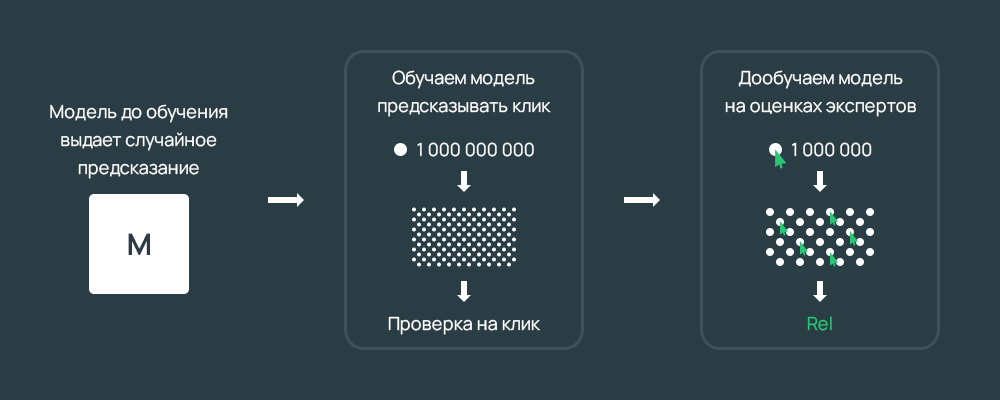
Сеть YATI обучается по такому алгоритму:
- Сначала учится свойствам языка, решая задачу Masked Language Model, но обучается сразу на текстах, характерных для задачи ранжирования. Уже на этом этапе вход модели состоит из запроса и документа, и Яндекс с самого начала обучает модель предсказывать еще и вероятность клика на документ по запросу;
- Далее происходит дополнительное обучение модели на более простых и дешёвых толокерских оценках релевантности количестве;
- Затем на более сложных и дорогих оценках асессоров;
- И наконец, обучается на итоговую метрику, которая объединяет в себе сразу несколько аспектов. По итоговой метрике Яндекс оценивает качество ранжирования.
На вход модели подаются те же контентные признаки, о которых шла речь в самом начале. Конкретно:
- Текст запроса, а также расширения;
- Фрагменты содержимого документа;
- Стримы.
Документ целиком пока не анализируется. Поисковая система разбивает страницы на зоны: основное содержание, заголовки и так далее.
Тяжелые модели слишком дороги в реализации. Поэтому в Яндексе создали легкие модели, которые пародируют тяжелые. Простой модель копирует поведение более сложной, обучаясь на предсказания в офлайне. В результате качество поиска падает, но не критично. Скорость расчета растет критично.

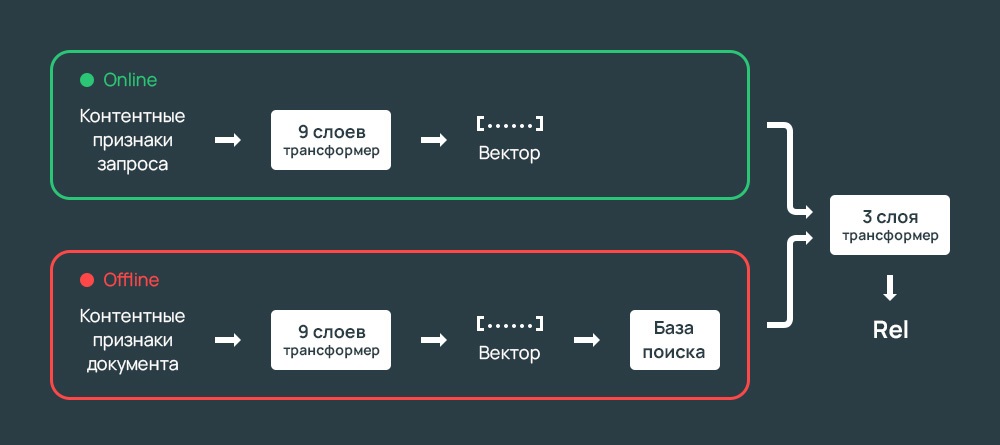
В Яндекс разделили модели на онлайн и оффлайн, чтобы нагрузка была низкой и качество поиска было высоким.
Схема:
- Часть модели применяется только к запросу.
- Часть — только к документу;
- Что получилось, затем обрабатывается финальной связывающей модель.
YATI и SEO
По мере внедрения YATI трафик из поисковой выдачи будет перетекать от мелких сайтов, заточенных по низкочастотные ключевые фразы, к крупным авторитетным сайтам.
Важные нюансы
Большое количество неинтересных для поиска страниц на сайте способно снизить релевантность действительно важных страниц.
Яндекс:
Модель вполне может выучивать свойства хоста как целого и использовать это как первое приближение к ответу. Тогда ей потребуется больше «сигнала», чтобы преодолеть такое выученное смещение.

Текст следует делить на информативные заголовки.
Яндекс:
Текущий алгоритм в первую очередь выделяет области с основным текстовым содержанием (содержание статьи, описание товара в магазине, etc) и дополнительно смотрит на общую структуру, включая заголовки разделов. При этом может использоваться как вся доступная нам разметка и структура на веб-странице, так и структура самого текста (т.е. не размеченная явно, но понятная из синтаксиса и содержания). Поэтому у страницы должно быть хорошее текстовое содержание, которое (при большом объеме текста) логично поделено на разделы с информативными заголовками. Явная разметка упростит задачу для наших алгоритмов. Если текста немного (условно 10 предложений или меньше), то мы скорее всего просто «прочитаем» его целиком и никакого дополнительного деления не требуется.
Сегментация текста нужна для правильного выбор информации, которая затем подается в модель.
Яндекс:
Подчеркну, что сегментация используется только для выделения фрагментов, которые мы покажем модели, но не для оценки их относительной значимости. Это «решает» уже модель. Например, в конкретном случае модель вполне может решить что текст размеченный как заголовок на самом деле не информативен, и тогда он не повлияет на предсказание.
Пересчет релевантности страницы происходит после переиндексации страницы сайта.
Расчет модели происходит при каждом переобходе страницы, частота которого зависит от разных факторов. Если содержимое страницы не поменялось, то переобход для модели YATI ничего не изменит — произойдет повторное применение к тем же фрагментам текста, что и раньше.
Как подготовить сайт к системе ранжирования YATI?
При ранжировании трансформеры позволяют добиться нового уровня качества при моделировании семантической связи запроса и документа, а также дают возможность извлекать полезную для поиска информацию из более длинных текстов.
Из логики алгоритма следует, что надо создавать страницы с расширенным семантическим ядром. Вместо количества делать акцент на качество.

Требуется адаптировать формат текстов под текст для людей и расширить семантические ядра страниц. Как? Например, так:
- Расширить семантическое ядро вхождениями релевантных ключевых фраз из поисковой видимости;
- Найти поисковые запросы из систем аналитики, по которым был привлечен трафик на сайт, добавить релевантные фразы в контент;
- Добавить в текст релевантные фразы из поисковых подсказок. В подсказках появляются низкочастотные фразы, которых нет в других системах;
- Проверить логи внутреннего поиска и добавлять в контент найденные релевантные ключевые фразы.
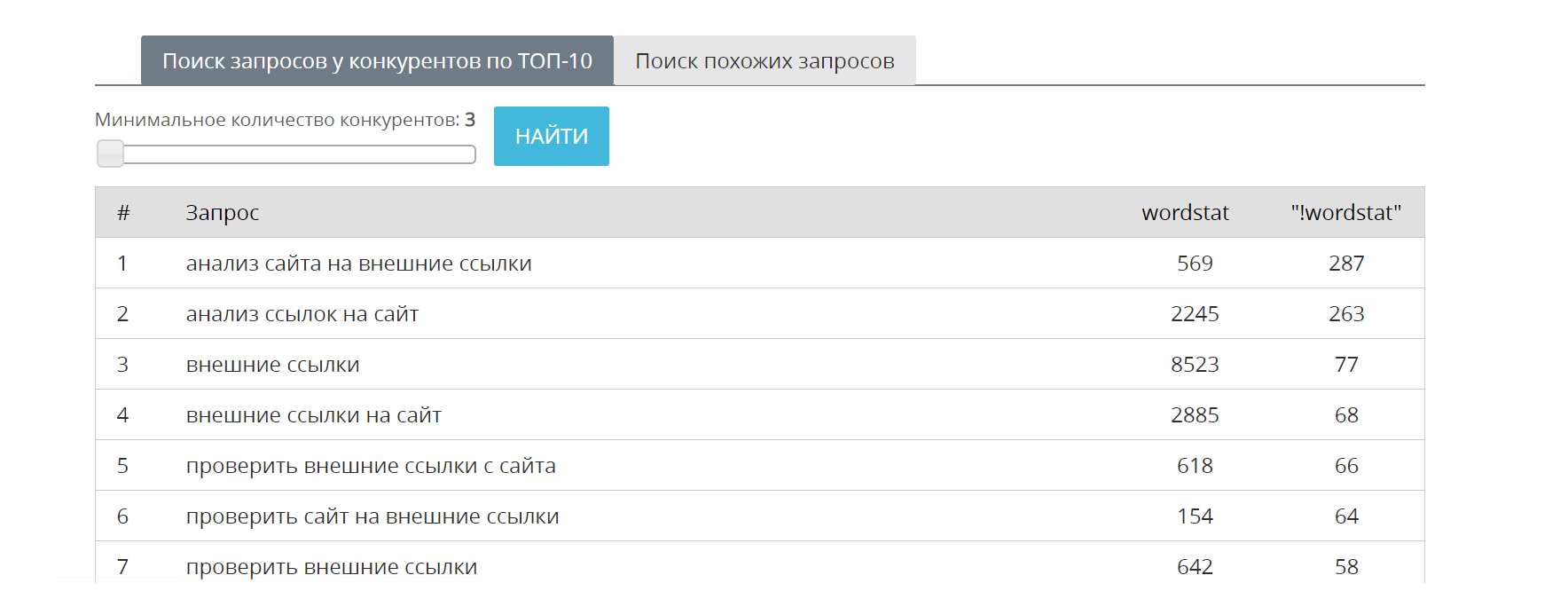
Как выгрузить ключевые фразы из поисковой видимости? Самый простой способ заключается в выгрузке данных из базы MegaIndex.
Как этот способ работает? Робот MegaIndex регулярно сканирует поисковую выдачу, чтобы собирать и обновлять списки ключевых фраз, по которым ранжируются страницы. Результат сохраняется в базу. В результате сервис позволяет находить релевантными ключевые фразы, которые следует добавить на страницу.
Ссылка на сервис — Поиск похожих фраз.
Сервис бесплатный.
Пример:
Рекомендованный материал в блоге MegaIndex по теме расширения списка ключевых фраз похожими по ссылке далее — Как находить дополнительные ключевые фразы, чтобы привлечь больше трафика?
Выводы
В поисковой системе Яндекс разработана нейросетевая архитектура для ранжирования. Название — Yet Another Transformer with Improvements.
Система анализирует разные блоки текста на странице сайта.

Задача система заключается в анализе соответствия смысла запроса и смысла текста на странице.
Алгоритм способен:
- Анализировать как короткое содержание, так очень длинные тексты;
- Определять самые значимые фрагменты текста на странице сайта;
- Учитывать порядок слов, и учитывать контекст. Важно, например, при поиске билетов.
Благодаря трансформерам алгоритмы стали лучше оценивать смысловую связь между запросами пользователей и содержанием документов.
Яндекс:
Внедрение принесло рекордные улучшения в ранжировании за последние 10 лет (со времён внедрения Матрикснета). Просто для сравнения: Палех и Королёв вместе повлияли на поиск меньше, чем новая модель на трансформерах. Более того, в поиске рассчитываются тысячи факторов, но если выключить их все и оставить только новую модель, то качество ранжирования по основной офлайн-метрике упадёт лишь на 4-5%!
Похожая идея чуть легла в основу проекта BERT (Bidirectional Encoder Representations from Transformers) от Google. Рекомендованные материалы в блоге MegaIndex на тему алгоритма от Google по ссылкам далее:
- Google BERT — новый поисковый алгоритм. Как изменится ранжирование и что делать сейчас?;
- Разрушаем главные мифы про новый алгоритм Google BERT.
Крайне интересное обновление. Что делать? Если просто, то владельцам сайтов следует:
- Заняться повышением качества текстов. Учитывать похожие поисковые запросы и стримы;
- Поделить страницу на секции, так чтобы у модели или у сегментатора было больше очевидных структурных признаков, которые можно использовать при анализе.
Найти похожие запросы помогает сервис MegaIndex. Ссылка на сервис — Поиск похожих фраз. Сервис бесплатный.
Раньше мы сообщали, что Yandex планирует внедрять аналог BERT. Технология начала работать в Яндекс поиске с осени 2020-года для всех запросов. Следующий этап в расширении зоны анализа до всего документа.
Остались ли у вас вопросы, замечания или комментарии? Что вы думаете о Yandex YATI? Напишите в комментариях.
Обсуждение
Цитата:
"По мере внедрения YATI трафик из поисковой выдачи будет перетекать от мелких сайтов, заточенных по низкочастотные ключевые фразы, к крупным авторитетным сайтам."
Похожая идея чуть легла в основу проекта BERT (Bidirectional Encoder Representations from Transformers) от Google.
А на счет алгоритмов я вообще статью не читал. Все больше приходит осознание создания контента и сайтов качественных, с вложением времени и средств. Вы же не будете бегать по всем сайтам и править их в угоду новым алгоритмам )) Делай качество и оно проживет очень долго при многих алгоритмах. Человеку тягаться с алгоритмами нет смысла, а вот делать качество всегда в почете!
Судиться с ворами почти бесполезно, имя статейникам Легион. Надёжного способа заверить свой текст как первоисточник в глазах поисковой системы не существует, т.о. защиты от воров нормальной нет. Это война где ты вкладываешь многочасовой труд, а твои соперники пару кликов мышкой в спец.софте.
Еще минус 1 позиция :)
\
А в гугле наоборот стло +250 запросов в топ 50
Яндекс мой сайт свалил вниз. СЕйчас в яшке выживаю только за счет яндекс директа 1000 руб в сутки трачу чтобы быть по всем запросам на первой страничке. Короче если хотите в топ у яндекса то только директ плАчу и плачУ! плачУ и плАчу
Ну теперь понятно чо, почему у людей сайты сыпятся после нашествия этих баранов и я даже боюсь представить как будет работать Яти если она опирается на данные стада баранов, которые за 2 копейки спустя рукава кое как НЕ выполняют задания . а открывают и сразу закрывают страницу. Странно, что руководство яндекса так халатно относится к этому, не следит и более того, еще и в основу для алгоритмов берёт инфу. Просто нет слов.
Алгоритмы все лучше, а выдача все хуже. Вот это я понимаю - инвестиции!!!
Всевозможные "Магаданы", "Краснодары" и "Минусински", портянки, микроразметка рулит, Яндекс.Острова, нейросетевой поиск, отзывы рулят, асессоры и толока, картинки рулят - да все их идеи и не вспомнить. И что в итоге?
А в итоге мы имеем в топах сервисы самого Яндекса и его партнеров. агрегаторы и маркетплейсы, государственные ресурсы, ну и немножко информации, сомнительной в плане актуальности, от каких-то неведомых пейсателей-копирайтеров, одобренной "асессорами", но имеющей не так уж много общего с реальностью.
Новый алгоритм ранжирования? О-о. Ну, ждите, что в топе станет еще на пару мест меньше.
Ничего не понятно, но ооочень интересно.
Ничего не понятно, но ооочень НЕ ИНТЕРЕСНО