
Как удалить страницы из поисковой выдачи?
Зачем удалять страницы?
Какие страницы следует удалить из поисковых систем?
Разберемся с вопросами далее.
Как удалить страницы из поисковой выдачи Google и Yandex?
Есть различные способы, применяя которые можно удалить страницы из индекса поисковых систем. Но есть важные нюансы.
Главные способы такие:
- Директива noindex. Применение данной директивы допустимо в метатегах и HTTP-заголовках. Директива noindex является наиболее эффективным способом удаления страниц из индекса, если сканирование страниц разрешено в принципе;
- 404 и 410 HTTP коды ответа сервера.
- Директива Disallow в файле robots.txt. Есть важный нюансы. Ошибка с использованием директивы disallow зачастую приводит к проблемам с ранжированием;
- Защиты паролем;
- Google Search Console Remove URL. Инструмент является простым и быстрым способом удалить страницу из результатов поисковой выдачи. Но есть нюансы;
Способ 1 — Noindex
Директива noindex поддерживается поисковыми системами только в тех случаях, если запись прописана в метатеге и/или HTTP-ответе страницы.
Ранее применение директивы допускалось в файле robots.txt. Но стандарт Robots Exclusion Protocol был изменен и теперь использование директивы в файле является недопустимым.
Рекомендованный материал в блоге MegaIndex по теме robots.txt по ссылке далее — Google обновляет правила для robots.txt. Что изменится и что делать?
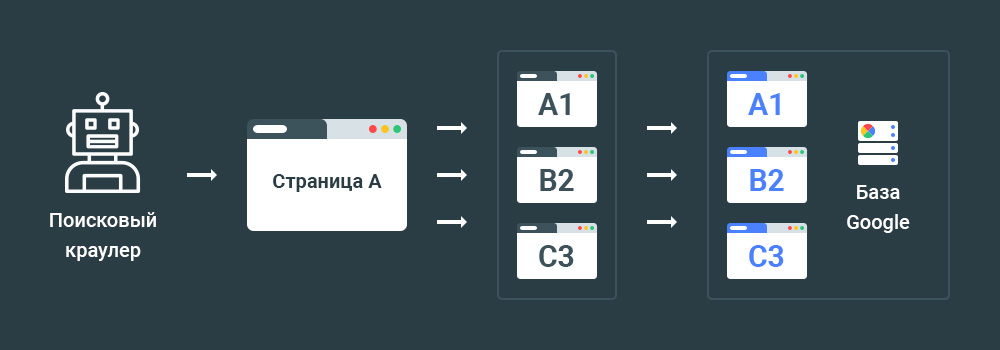
На практике для запрета индексации следует использовать метатег robots. Например, если для сайта indexoid требуется запретить индексацию страницы, то на страницах подлежащих запрету следует использовать такой код:
<meta name="robots" content="noindex">
Если требуется запретить индексацию страницы применяя для этого HTTP-заголовок, то в коде ответа сервера следует указать следующее:
X-Robots-Tag: noindex
Пример кода ответа сервера:
HTTP/1.1 200 OK
Date: Tue, 25 May 2010 21:42:43 GMT
X-Robots-Tag: noindex
Как результат, поисковая система удалит страницы из индекса после следующей итерации краулинга.
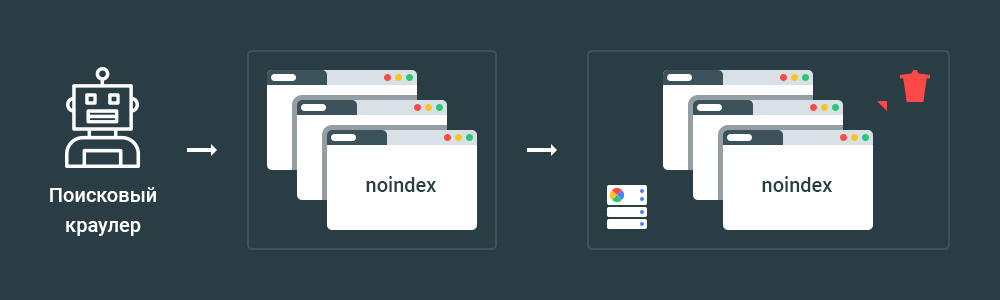
Способ 2 — 404 и 410 HTTP коды ответа сервера
Как инструмент для запрета индексации можно использовать 404 и 410 HTTP коды ответа сервера.
Оба кода означают, что страница не существует:
- 404 Not Found/Страница не найдена;
- 410 Gone/Страница удалена.
Рекомендованный материал в блоге MegaIndex по теме процесса краулинга по ссылке далее — Google обновил поисковый краулер. Что изменилось? Как это повлияет на ранжирование?
Поисковые системы такие как Google и Yandex удаляют такие страницы после повторного краулинга и обработки.

Способ 3 — Disallow в файле robots.txt
Директива Disallow поддерживается стандартом Robots Exclusion Protocol.
Применяя данную директиву можно задать список страниц, которые поисковому краулеру следует игнорировать, то есть не посещать.
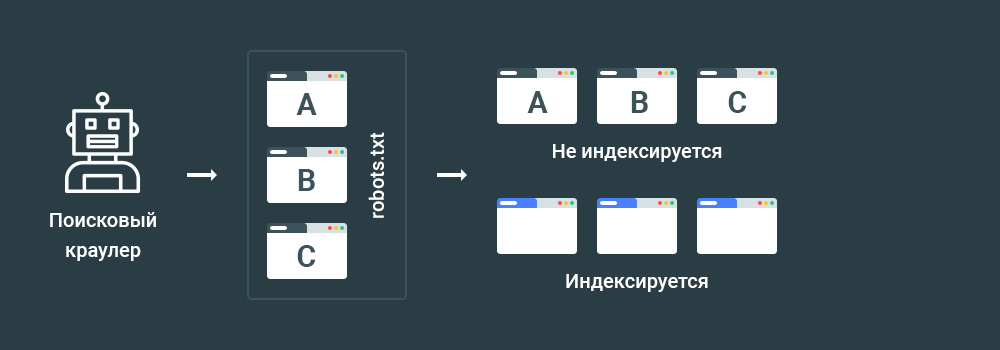
Но есть важный нюанс.
Несмотря на запрет директивы Disallow, страницы сайта все равно могут быть добавлены в индекс, если на такие страницы есть ссылки с других страниц. Данная информация является проверенной на практике.
В результате такой подход является неэффективным.
Итак, директива Disallow используется для указания ссылок на страницы, которые не должны быть проиндексированы, но контент все же может попасть в индекс. К примеру, в случае наличия любых открытых ссылок на закрытые страницы с других страниц.
Способ 4 — Защита страниц паролем
Защита страницы паролем не позволяет поисковой системе получить доступ к содержанию страницы сайта.
Такая защита обычно используется для ограничения доступа к разделам сайта, которые доступны по модели платной подписки.
Поисковые системы индексируют страницы защищенные паролем, на зачастую удаляют такие страницы из индекса.
Способ 5 — Google Search Console Remove URL
Инструменты от поисковых систем позволяют исключить страницы из индекса, но есть нюансы.
Применяя инструменты поисковых систем страницы сайта можно исключить из индекса, но на временной основе.
Значит в перспективе такие страницы будут проиндексированы снова.
Еще данный способ требует подтверждения прав на сайт, поэтому не всегда удобно использовать такой инструмент. В частности такой способ усложняет работу, если речь про частную сеть сайтов.
Рекомендованный материал в блоге MegaIndex на тему PBN по ссылке далее — Как построить частную сеть сайтов для SEO. PBN сайты в поисковой оптимизации.
Ссылка на инструмент Google — Google URL Removal.
Применяя данный инструмент на практике удалить страницу сайта можно как из индекса, так и из кеша поисковой системы.
Ссылка на инструмент Yandex — Удаление страниц из поиска.
Какие страницы следует удалить из поисковой выдачи? Для достижения каких целей такие страницы следует удалить из индекса поисковой системы?
Какие страницы следует удалить из индекса? Зачем?
Из поисковых систем Google и Yandex следует удалить все ненужные страницы.
Под ненужными страницами подразумеваются страницы, по которым не планируется привлечения трафика из поисковой выдачи.
Зачем удалить страницы? Есть ряд причин для таких действий.
Например, цели могут быть следующие:
- Улучшение хостовых поведенческих факторов на поисковой выдаче.
- Скрытие анкет пользователей и защита от парсинга клиентской базы или e-mail;
- Безопасность;
- Удаление из индекса страниц копий;
- Замена сайта. Например, при регистрации освобожденного доменного имени для последующего создания на нем нового сайта;
- Повышение релевантности контента сайта в отношении тематики;
Что такое хостовые факторы на поисковой выдаче? В алгоритмах поискового ранжирования используются различные данные, включая данные о действиях пользователей на выдаче. Информация об этом следует из практики и патентов поисковых систем.
Итак, под хостовыми факторами на поисковой выдаче подразумеваются такие факторы как:
- Среднее значение СTR страниц;
- Среднее значение Dwell Time;
- Прочее.
Рекомендованный материал в блоге MegaIndex на тему патентов Google по ссылке далее — Google запатентовал поведенческие факторы: что нужно знать и что делать?
Что такое Dwell Time? Рекомендованный материал в блоге MegaIndex по теме Dwell Time по ссылке далее — Dwell Time (Длина клика) — что это за фактор ранжирования и как его оптимизировать?
Итак, если в поисковой выдаче находится множество страниц по которым не бывает кликов, то значение хостовых факторов на поисковой выдаче занижается.

Если в поисковой выдаче находятся только те страницы, которые должны привлекать трафик, то значение хостовых факторов на поисковой выдаче будет выше.

На открытых к индексации страницах сайта следует провести комплекс мер по улучшению сниппетов. Инвестиции в оптимизацию сниппетов проводят к повышению метрики кликабальности и улучшению поведенческих факторов на выдаче.
Идеи по созданию кликабельных сниппетов можно подсмотреть у конкурентов, или у компаний с большими бюджетами на маркетинг. Например, если вы продвигаете автосалон в регионе, вы можете посмотреть как сделаны сниппеты на сайте московского автосалона.
MegaIndex индексирует сниппеты всех сайтов в интернете и предоставляет пользователям собранные данные о сниппетах всех сайтов в сервисе анализа сниппетов.
Ссылка на сервис — Анализ сниппетов.
Пример использования сервиса:
Вопросы и ответы
Через какое время страницы будут удалены из поисковой выдачи?
Страницы будут удалены после переиндексации. Иными словами, после визита краулера и дальнейшей обработки страниц поисковой системой.
На практике переиндексацию можно ускорить.
Рекомендованный материал в блоге MegaIndex по теме индексации по ссылке далее — Как добавить страницы сайта в поисковую выдачу? Нестандартные способы.
Следует ли удалять из поисковой выдачи дубли страниц?
Следует удалить копии страниц.
Дубли страниц из поисковой выдачи удалять не следует.
В чем разница между дублем и копией страницы?
Google различает дубликаты (duplicate) и копии (copy) контента.
Сайты с копиями подвергаются санкциям от поисковой системы.
К скопированному контенту относятся все виды контента с уникализацией. Например:
- Spinning content;
- Контент с заменой слов (если заменить в тексте слово "найти" на "поиск", то контент останется копией);
- Контент содержащий набор копий из разных источников;
- Страницы копирующие контент с динамических страниц.
Дубликаты не подвергаются санкциям и даже могут ранжироваться выше за оригинал.
Дубликатом считается скопированный контент, но с добавочной ценностью.
Выводы
Какие страницы не должны находиться в индексе поисковых систем? В индексе не должны находиться ненужные страницы. Зачастую в индексе находятся различные страницы, по которым не планируется привлечение трафика. Такие страницы являются ненужными.
Почему в индексе поисковых систем должны быть не все страницы? Есть различные причины. Как пример, исключение ненужных страниц позволяет улучшить релевантность сайта, удалить копии, улучшить поведенческие хостовые факторы на выдаче.
Как удалить ненужные страницы из индекса? Есть 5 основных способов для удаления страниц из поисковой выдачи:
- Директива noindex;
- Коды ответа сервера 404 и 410;
- Директива Disallow;
- Защита страниц паролем.
- Инструменты поисковых систем.
В чем разница? Какие способы являются наиболее эффективными? Итак, есть ряд способов для удаления страниц из индекса. Но есть нюансы, ввиду которых некоторые способы по удалению страниц из выдачи различаются по эффективности.
Директива Disallow указывает поисковому краулеру на то, что в индексации контента нет необходимости. Такие страницы все равно могут быть проиндексированы. Например, в случае наличия ссылок на такие страницы с других страниц.
Итак, использование директивы Disallow в файле robots.txt для скрытия страниц сайта, которые находятся в разработке является ошибкой. Скрытые страницы все равно могут попадать в индекс поисковых систем.
Защита страниц паролем является эффективным способом, но создает сложности для пользователей.
Инструменты поисковых систем Google и Yandex позволяют быстро удалить из индекса страницы сайта, но страницы вновь появятся в индексе после следующей волны индексации.
Наиболее эффективными способами для удаления URL из поисковой выдачи являются такие — директива noindex и 404, 410 коды ответа сервера.
Размещение директивы noindex допускается в метатеге и HTTP-заголовке X-Robots-Tag. Директиву следует размещать на каждой странице, которая подлежит исключению из индекса.
Применение директивы noindex и/или кодов ответа сервера 404 и 410 позволяет исключить страницы из поисковой выдачи сразу после следующей волны индексации. Статус коды 404 и 410 не указывают на запрет индексации как таковой, но позволяют исключить страницы из индекса Google и Yandex.
Мусорные страницы следует удалить из поисковой выдачи, так как наличие таких страниц в индексе приводит к ряду проблем при продвижении сайта. Например, к занижению поведенческих факторов на выдаче, что приводит к занижению хостовых факторов и сказывается на ранжировании.
Остались ли у вас вопросы, замечания или комментарии по теме удаления страниц из индекса поисковых систем?
Обсуждение
Как лучше поступить ?
на много дублирующего контента
Например в моей тематике ключи:
индийский ресторан в москве
индийский ресторан
ресторан индийской кухни в москве
ресторан индийской кухни
индийский ресторан в москве адреса
индийское кафе в москве
кафе индийской кухни в москве
индийское кафе
тут было создано ранее 3 статьи - Рестораны, Кафе, Кухни
Но в выдачи так всё идентично и синонемы.
Вот сейчас хочу чисткой заняться, и создать / переделать на 1 статью. Будет ли эффект ?
Каждый день удаляю по 50-300 страниц.
Сейчас на них ставлю 301 редирект и на переобход в ВебМастере Яндекса. Это работает? Страницы почему то из индекса не уходят, судя по ВебМастеру, хотя удалил уже 1000+++
Может лучше 404 и 410 HTTP коды ответа сервера? Но опасаюсь что яндекс подумает, что на сайте много битых ссылок, которые есть у него в индексе.
Если 301-ый редирект ведет на тематическую страницу, то нет проблем.
Вы проверяли код ответа, действительно ли выдается 301?
В данном случае следует проверить по логам, посещал ли краулер такие страницу.
Все эти урлы каталогом были добавлены в удаление Яндекса и Гугла. Яндекс удалил это все через сутки и давно забыл.
Гугл написал, что тоже удил - ок. Но уже прошло 3 месяца, и он до сих под долбится в эти страницы. На сайте их давно нет. Поставить им 410 или 410, или пароль или все что вы написали - НЕ ВОЗМОЖНО.
Как удалить из индекса Гугла эти страницы? Как показать боту что их давно нет, не надо в них долбится и получать 404 вместо того, что бы обходить нормальные рабочие карточки товаров?
Я все это вижу в Серч Консоли, где бот каждый день пишет, просканировано на запрет в роботс (да, этот каталог был закрыт в роботс в тот момент, когда оправили каталог на удаление в оба вебмастера). Да, я вижу все в это логах.
Так что делать?
Примитивная задача.
Как решение, проверьте есть ли внешние ссылки на такие страницы и измените на новые - https://ru.megaindex.com/backlinks?from=264.
И внешних ссылок на эти страницы нет.
Вы в своих статьях описываете самые стандартные способы. которые просто взяли и зарерарйтили из официальных источников.
А то, что возникает не стандартное вы профессионалы никто ничего не не может ответить и не знает. Потому как в этим не сталкивались. Переписывание чужих мануалов ничему не научит - как показывает практика.
А еще надо учитывать то, что инструмент удаление урлов от гугла - временный Там так и написано - скрыть на время. А что же дальше происходит? На какое время? Этого в манулае нет, и поэтому никто ничего не знает, увы.
А гугл как ходил по этим страницам уже удаленным через его панель временно, как получал 404 таки получает. И ссылок на эти страницы нет.
Вы использовали главные способы, которые описаны в статье?
Если на оба вопроса ответ да, то есть смысл продолжать. Практика показывает, что если все советы применяются, то результат есть. Так на моих сайтах.
Практика показывает, что никто не знает что делать. И лишь один человек мне подсказал, что надо использовать апи гугла для индексирования, где есть команда удаления. Конечно, для этого все го нужен программист.
А просто так, все что выше описали - и звените не помогает.
Способы описанные выше обычно помогают. Я их использовал, у меня никаких проблем не было. В случае проблем я бы обратился в Google.
В блоке "Вопросы и ответы" под заголовком "Как быстро страницы будут удалены из поисковой выдачи?" нет ответа - как быстро. Там говорится о том, когда будут удаляться страницы с точки зрения алгоритма, но как о том как быстро или как долго - не понятно. Не говорю, что нужно писать именно сколько времени пройдет для удаления, потому что точно сложно сказать, много нюансов. Но хотяб заголовок подредактировать будет хорошо)
И еще по поводу того, что удалять все страницы, не нацеленные на привлечение органики: а как же страницы, типа "О компании", "Контакты", "Прайс-лист" и любые другие страницы, влияющие на комм. факторы? Думаю, если их удалить, то эффект будет скорее отрицательный (не пробовал, и не буду скорее всего)).
Ничего не делать тоже было бы не правильным шагом.
На такие страницы следует добавить ключевые фразы.
Даже если фразы с низкой частотностью.