

Что запатентовал Google? Какие сигналы ранжирования описаны в патенте? Что следует сделать?
Разберемся с содержанием патента далее.
Google запатентовал поведенческие факторы
Что произошло? 12 марта 2019 года Google получил патент под названием Modifying search result ranking based on implicit user feedback.
Из названия ясно, что в патенте речь идет про технологию, которая используется для изменения ранжирования результатов поиска на основе неявной обратной связи с пользователем.
Ссылка на патент — Modifying search result ranking based on implicit user feedback.
Исходя из закона об авторском праве, патенты должны находиться в открытом доступе. Так у поисковых оптимизаторов появляется шанс разобраться в тонкостях ранжирования, которые поисковая система может использовать на практике.
В патенте описывается процесс сбора и анализа поведенческих факторов. Наиболее интересным элементом является так называемый Rank Modifier Engine, то есть система корректировки ранжирования.
Что такое Rank Modifier Engine?
Итак, исходя и описанной в патенте технологии существует две системы ранжирования сайтов:
- Корневая система ранжирования страниц сайтов;
- Система корректировки ранжирования (Rank Modifier Engine).
Система корректировки ранжирования работает отдельно и автономно от основной системы ранжирования.
Процесс выглядит следующим образом:
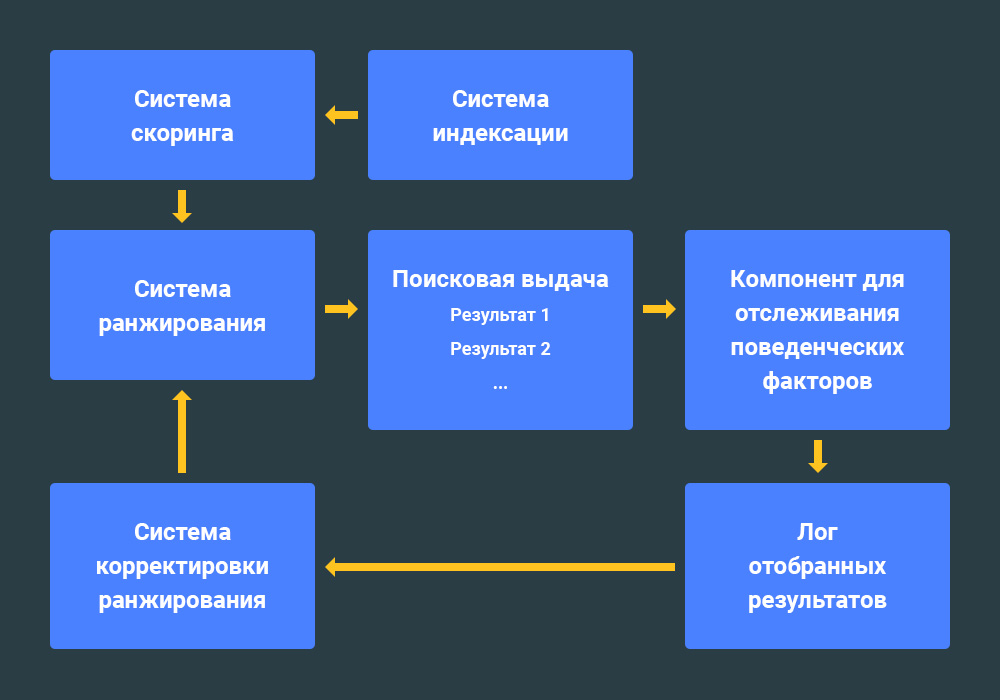
Основная система ранжирования получает так называемую меру релевантности страницы из системы корректировки ранжирования. В результате позиции в поисковой выдаче изменяются.
Но какую информацию обрабатывает система корректировки ранжирования и как именно? Разберемся далее.
Как работает система корректировки ранжирования?
В патенте описываются сигналы, которые поисковая система может использовать при ранжировании сайтов. Разберемся с главными нюансами.
В патенте речь идет про следующие сигналы ранжирования:
- Кликовые поведенческие факторы. Речь про факторы, связанные с поведением пользователя на странице поисковой выдачи. В патенте описывается анализ кликстрима, расчет CTR документа по запросу и прочее;
- Фактор длины клика. Согласно патенту, анализируется время, проведенное пользователем на выбранной странице сайта (a time the user spent on the document). В среде поисковых оптимизаторов метрика именуется как dwell time. Под временем, потраченным пользователем на странице сайта, подразумевается время, прошедшее от клика на ссылку в органических результатах до возвращения к поисковой выдаче и выбора нового документа.
- Язык и страна пользователя. Использование данного фактора указывает на дифференцирование результатов выдачи в зависимости от языка и предполагаемой страны. К примеру, результаты выдачи для запросов на русском языке и на украинском языке могут отличаться по причине использования разного языка в интерфейсе. Значит, от правильной настройки мультиязычности на сайте зависят позиции в поисковой выдаче. Если перелинковка настроена не верно, то по запросам с одинаковым интентом могут быть потеряны позиции. Если на сайте используется множество языков и перелинковка настроена правильно, то по схожим запросам будет выводиться один и тот же сайт, но ссылки будут разными.
Кликовые факторы ранжирования в патенте расписаны подробно. Срезы по длине клика следующие:
- Запрос-документ;
- Запрос-документ-язык;
- Запрос-документ-язык-страна.
По длине клики разбиваются на такие группы:
- Короткие;
- Средние;
- Длинные;
- Последний клик.
Итак, определено понятие последнего клика.
Последним кликом называется клик, после которого пользователь не возвращается на страницу с результатами выдачи.
Что можно считать коротким, что средним и что длинным кликом? Значение для каждой из групп зависит от запроса. Итак, для каждого запроса есть свои значения, и конкретные цифры определяются исходя из поведения пользователей на практике.
Как результат, исходя из данных о длине клике поисковым алгоритмом оценивается то, насколько хорошо страница отвечает на поисковый запрос.
В патенте приводится следующий пример:
- Короткий клик может считаться плохим показателем для страницы. Страница плохо отвечает на поисковый запрос. Пример значения — 0,1;
- Средний клик характеризует страницу как потенциально полезную. Пример значения — 0,5;
- Длинный клик характеризует страницу как хорошую. Пример значения — 1,0;
- Последний клик характеризует страницу как вероятно хорошую. Пример значения — 0,9.
При анализе кликов меньший вес назначается кликам тех пользователей, которые чаще остальных выбирают высоко ранжируемые страницы. Иными словами, если пользователь постоянно выбирает результаты из топ-3, то значимость клика снижается.
Помимо оценки поведения на выдаче, пользователей также разделяют на обычных и опытных. Как результат, при учете кликов определенного пользователя используется весовой коэффициент. Значение зависит от индивидуального поведения в интернете.
Пользователь может быть классифицирован на основе запросов, которые отправляют в поисковую систему. В частности, предполагается, что пользователь является опытным в нише, если вводит множество запросов по определенной нише.
Какой вывод можно сделать? Значит, использование мотивированного трафика из специальных сервисов заведомо ниже по эффективности, нежели привлечение целевой аудитории в выдачу из социальных сетей или оптимизация сниппетов и прочее.
Какие еще нюансы по анализу выдачи известны из патента? На основе полученных данных поисковой системе требуется получить информацию о том, какие страницы лучше отвечают на запрос, и какие хуже. Но если использовать данные напрямую, то ввиду естественного распределения страницы из топ-3 будут получать больше переходов из поисковой выдачи, и, как следствие, выдача не будет изменяться.
Как тогда решить вопрос определения релевантных страниц, исходя из полученных данных? Решение заключается в следующем. При расчете значения релевантности используются составные показатели.
Примеры составных показателей:
- Отношение числа длинных кликов к коротким;
- Отношение числа длинных кликов ко всем кликам для конкретного документа по конкретному запросу (доля длинных кликов).
В качестве защиты от шума к подобным отношениям может быть добавлен параметр сглаживания.
Параметр сглаживания обладает следующим свойством — если общее количество кликов невелико, то результат будет стремиться к нулю.
Сигнал не будет учитываться, да и все. Я выдвигал гипотезу о таком подходе поисковой системы в комментариях к статье про поведенческие факторы. Ссылка на статью — Фактор ранжирования Dwell Time — что это и как его оптимизировать для роста позиций в выдаче? Теперь гипотеза подтверждена патентом.
Как результат, благодаря составным показателям, страницы получающие относительно небольшое количество кликов, но длинных в итоге могут получить больший вес меры релевантности, нежели страницы, находящиеся в топ-3 и получающие относительно большое количество кликов, но коротких.
Итак, на меру релевантности влияет соотношение:
количество длинных кликов/общее количество кликов*100
Параметры сглаживания могут варьироваться в зависимости от языка или страны.
Как происходит влияние на ранжирование? Исходя из патента, вычисленные значения меры релевантности (в явном или преобразованном виде) предлагается применять в качестве повышающего коэффициента к значениям релевантности, вычисленным алгоритмом ранжирования.
Значит, поведенческие факторы влияют на результаты ранжирования страниц в органической выдаче поисковой системы.
Схема из содержания патента:
Вопросы и ответы
Используются ли поведенческие факторы в Yandex?
Да. Поведенческие факторы используются в Yandex. Есть подтверждения.
В поисковой системе поведенческие факторы именуются как пользовательские факторы ранжирования документов.

Признает ли Google использование поведенческих факторов?
Официальных заявлений об использовании поведенческих факторов ранжирования в поисковой системы Google нет.
Представители Google отрицали использование таких факторов. Заявления исходили не от инженеров из Google Search Team, а от службы поддержки. В заявлении было сказано, что поведенческие и социальные факторы с точки зрения разработчиков алгоритма ранжирования Google являются очень плохими и слишком шумными сигналами и поэтому не учитываются в алгоритме.
С высокой вероятностью данная информация не является достоверной и была вброшена намеренно с целью ввода поисковых оптимизаторов в заблуждение.
Другой представитель Google дезавуировал заявление:
Я не думаю, что он говорил о факторах напрямую.
Еще заявление от Google:
Если люди переходят на ваш сайт и заполняют формы или подписываются на услуги или рассылку, это значит, что вы действуете в верном направлении. Я бы рассматривал это как позитивный момент в целом, но это не значит, что Google учитывает эти действия в ранжировании и использует эту информацию для автоматического продвижения сайта.
Доступ к информации об использовании факторов ранжирования является ограниченным. Использование поведенческих факторов как сигнала ранжирования подтверждает:
- Официальные документы, такие как патенты;
- Практика.
На практике улучшение поведенческих факторов посредством улучшения сниппетов и дизайна влияет на ранжирование страницы сайта в поисковой выдаче.
Специальные сервисы по оптимизации поведенческих факторов также могут оказывать влияние на ранжирование сайтов. Для продвижения на подобных сервисах используется мотивированный трафик. Ссылка на такой сервис по оптимизации поведенческих факторов — SERP Click.
Выводы
Поведенческие факторы ранжирования в Google действительно используются при ранжировании сайтов. Об этом свидетельствуют соответствующие патенты и практика. Но если нет желания вникать в детали патента, то и не стоит.
Итак, получено еще одно подтверждение, что задача удержания пользователей на сайте является одной из основных задач в поисковой оптимизации.
Аналогичные выводы из содержания патента представлены в статье Сергея Людкевича.
Что делать? Просто используйте следующие рекомендации:
- Увеличьте количество переходов на сайт из поисковой выдачи за счет создания эффективных сниппетов. Например, проведите анализ сниппетов тематических сайтов, продвигаемых в регионах с высокой конкуренцией;
- Используйте специальную разметку для создания расширенных сниппетов в поисковой выдаче, чтобы привлечь трафик;
- Задерживайте пользователя на странице разными способами. Оптимизируйте Dwell Time, например используя формат страницы single-page content вместо пагинации.
Рекомендованные материалы в блоге MegaIndex:
- Как увеличить количество переходов на сайт из поисковой выдачи — Создание эффективных сниппетов;
- Как создать расширенные сниппеты, чтобы повысить трафик и позиции сайта?;
- Как создавать эффективные сниппеты и какая длина сниппета является оптимальной? + Мнения экспертов;
- Single-page content вместо пагинации;
- Фактор ранжирования Dwell Time — что это и как его оптимизировать для роста позиций в выдаче?
С чего начать? Например, используйте приложение Анализ сниппетов от MegaIndex, чтобы провести анализ сниппетов тематических сайтов, продвигаемых в регионах с высокой конкуренцией.
Ссылка на сервис — Анализ Сниппетов.
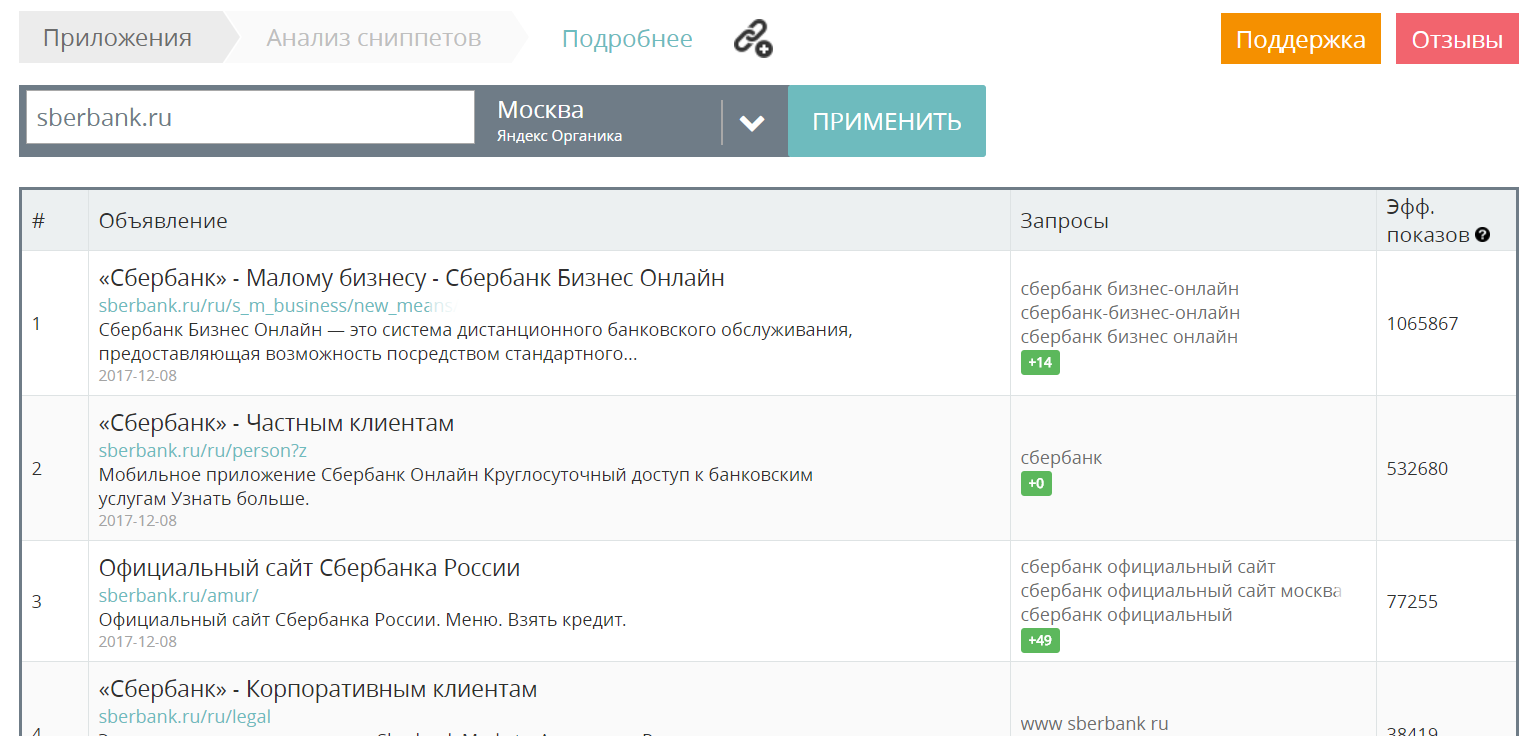
Есть API для получения сниппетов по домену. Для выгрузки данных через API надо использовать метод visrep/site_ser.
Пример запроса на выгрузку сниппетов из поисковой системы Google для сайта indexoid.
http://api.megaindex.com/visrep/site_ser?key=[ключ]&domain=indexoid.com&ser_id=1&count=10
Как переиндексировать страницу, чтобы обновить сниппет страницы на новый? Если сниппеты страниц откорректированы и требуется провести индексацию страницы заново, просто добавьте URL в сервис по оптимизации социальных сигналов GetSocial или Search Console.
А какие вы используете способы для удержания внимания пользователей на сайте?
Остались ли у вас вопросы, мнения, комментарии по теме патента Google на поведенческие факторы ранжирования?
Обсуждение
1. Если много коротких кликов, и страница отвечает на запрос — то хорошо. Будет присвоен последний клик;
2. Если ответ подразумевает углубленное изучение вопроса, больше длинных кликов — лучше.
И поясните пожалуйста вашу формулу меры релевантности, а то непонятно, что на что умножается и где промежуточные сведения и кликах, и их вершины.
"Что можно считать коротким, что средним и что длинным кликом? Значение для каждой из групп зависит от запроса. Итак, для каждого запроса есть свои значения, и конкретные цифры определяются исходя из поведения пользователей на практике."
А есть патенты.
1. Теперь Гугл конкретно занялся "контентным SEO" (в кавычках написал, потому что разговорный вариант, грубо говоря) и ввел новые "правила" (что ж, и не такое видали...).
2. От качества контента и его полноты (полнота раскрытия проблемы) зависит то, сколько пользователь останется на странице (в принципе, как и раньше, вот только теперь этот фактор, как я понял, имеет куда большую значимость, чем раньше).
3. Появился фактор последнего клика (это когда человек, к примеру, открыл до вашего сайта ещё 3, не нашел решения, и вот открывает ваш, находит ответ и больше не ищет информацию на своему вопросу) - это значит, что последний сайт, который посетил юзер, помог решить проблему (при том условии, что юзер пробыл на сайте не 5 секунд, а хоть какое-то время). А это значит, что сайт полезен. А если сайт полезен, то как обычно - его в ТОП (старая схема в новой обёртке).
4. Продвигать "мелким" контентом (2000-2500 символов без пробела, в которых написано "кратенько и обо всём") сайты теперь не вариант - проблему нужно раскрывать полностью, так что минималка для любой новостной статьи теперь уж точно 3500, а это означает увеличение объёма работ и повышение цены на контент как минимум на 5 тысяч рублей. Из этого пункта следует, что сайты бытовых услуг (мелкие сайты) пострадают больше всего (т.к. зачастую не готовы платить больше 5-7 тысяч в месяц веб-мастерам).
В общем, что и ожидалось. Но не думал, что так быстро это введут. Прогноз был где-то ещё на 5-8 месяцев запаса =_=...
И да, я по своим проектам заметил: куда лучше заходят небольшие (300-400 слов) тексты с хорошей силосованной структурой, чем длинные монографии, пусть и высокого качества.
В большинстве случаев, документ должен покрывать запрос пользователя и дополнительные возможны запросы, о которых пользователь может даже не знать, до перехода на документ из выдачи, но об этих запросах знает поисковая система.
Так что не думайте что «вот сейчас все поменялось», это глупости, машина гугла отлаживается оч долго и быстро менять ее невозможно.
Если пользователь не находит ответ, то ищет ответ на другой странице.
Если пользователь найдет ответ на другой странице быстро и страница является последней, то срабатывает опция "последний клик".
В патенте:
"Thus, in the discontinuous weighting case (and the continuous weighting case), the threshold(s) (or formula) for what constitutes a good click can be evaluated on query and user specific bases. For example, the query categories can include “navigational” and “informational”, where a navigational query is one for which a specific target page or site is likely desired (e.g., a query such as “BMW”), and an informational query is one for which many possible pages are equally useful (e.g., a query such as “George Washington’s Birthday”). Note that such categories may also be broken down into sub-categories as well, such as informational-quick and informational-slow: a person may only need a small amount of time on a page to gather the information they seek when the query is “George Washington’s Birthday”, but that same user may need a good deal more time to assess a result when the query is “Hilbert transform tutorial”."
Я могу говорить об этом с такой уверенностью потому, что для того, чтобы эти факторы учитывать нужно отправлять массу персонализированной информации о поведении посетителя на странице - персонализированной информации.
Никакая статистика поведения посетителя на сайте ни счетчиком гугла, ни браузером Google Chrome не отправляться.
Это легко проверяется как анализом трафика на уровне того что отправляют скрипты, так и на системном уровне снятием всего трафика от браузера. Что делают 24x7 многие специалисты.
Добавьте к этому тот факт, что Google работает в правовом поле громадного количества стран, где это прямо запрещено (отправка персонализированной информации), то есть за подобными вещами постоянно следят.
Так же стоит помнить - наличие патента не означает его внедрение.
Описанное выше в деталях патента, это общее фантазерство на тему как бы это могло быть реализовано. Зачем так делают? В силу особенности патентной системы, юристы кампаний стараются максимально обезопасить компанию от возможных патентных преследований.